There are thousands of reasons to bring census data into your workflow. Whether you are a retailer considering opening a store at a new location, an out-of-home advertiser considering investing in new billboards, a researcher from the CDC trying to identify risk-factors for cancer across a national patient population; all of these use cases (and many more) have one thing in common: you need to know demographic information about a place.
This is a beginners guide to working with Census Data. Using these instructions, you’ll be analyzing census data in 15 minutes or less.
Step 1: Download Open Census Data
The Census tracks a staggering amount of data, and all of this data is open and available to the public. Unfortunately, getting the data is not trivial. We’ve written about this problem before, and as a labor of love for the data science community SafeGraph painstakingly organized all of the data into a FREE and convenient single download of CSVs. SafeGraph didn’t add any frills or whistles or abstractions, and it doesn’t cost anything, we kept it simple. You should use this.
Once you have the data in hand, there are fundamentally 2 things you need to know to get going: what are the rows and what are the columns?
What Are The Rows?
Census data is organized geographically, and all of the Census and American Community Survey data can be keyed on the FIPS (Federal Information Processing Standards) geography code. The US government divides the USA into different nested boundaries: States > Counties > Census Tracts > Census Block Groups > Census Blocks.
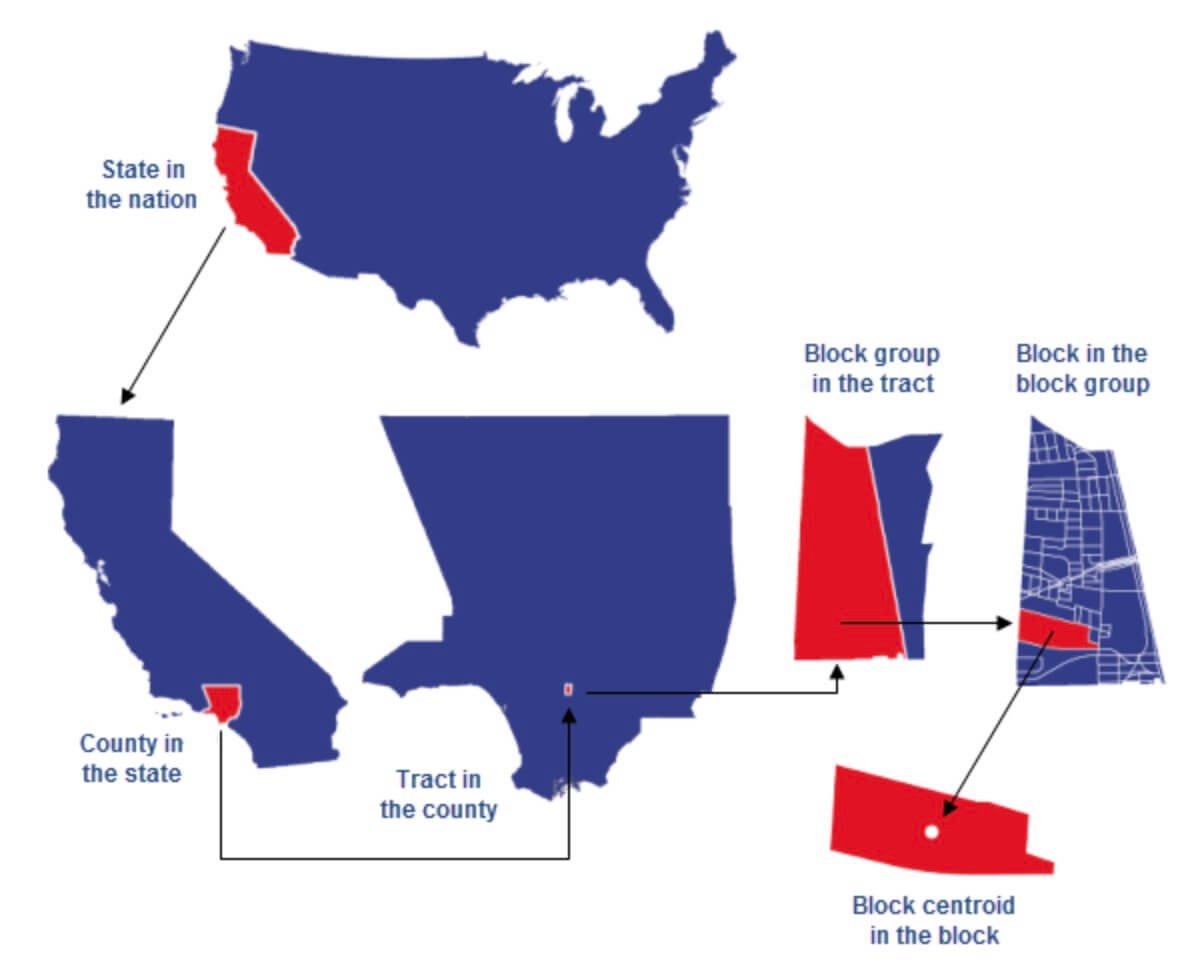
The census block group (CBG) is the highest granularity for which the Census reports most of its data, and so each CBG is a unique row in in the data.
The FIPS encodes all of this information for each census block group.
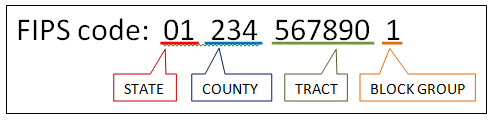
So, each row of the data is a unique census block group (CBG), encoded with a 12 digit FIPS code. And in Census data, the FIPS code (i.e., the primary key of the entire dataset) is listed in the column named `census_block_group`.
What are the columns?
Each “column” in the data is a particular census attribute estimated by the US Government (remember that each “row” is a unique census block group, or CBG). For example, one attribute is Sex By Age By Veteran Status For The Civilian Population 18 Years And Over which is a population estimate for civilians (non-veterans) over the age of 18. Since that is a mouthful, the government assigns each attribute a unique table_id code. In this example the table_id is B21001e7.
SafeGraph’s Open Census Data file includes over 7,500 table_ids (columns) for the 220,000+ census block groups in the US. It’s easy to get overwhelmed by Census data, but you probably do not need to analyze all of the Census data at once (or, you know, ever). So it is up to you to decide which Census attributes matter for your question.
To help wrap your head around the possibilities, let’s look closely at how the table_id code is organized. It encodes information about what type of code it is. For example the code B01001e19 encodes that this attribute is about Age and Sex, specifically the population estimate for Males aged 62 to 64 years.
Here is how that table_id code breaks down:
B01001e19 (encoded as B-01-001-e-19)
B = Table Type: This is a Base Table (as opposed to C for Collapsed Table)
01 = The Subject: Age; Sex
001 = The Specific Table: Sex by Age (002 is Median Age)
e = estimate (as opposed to m for margin of error)
19 = Specific Population: Males 62 – 64
You can read more about the meaning of the table_id code. However for most purposes you can generally consider these arbitrary short-hand codes for long variable names.
The metadata for each table_id located in /metadata/cbg_field_descriptions.csv. In addition to the full long variable names, this file also includes the subject and specific table broken out for each table_id. This is a very useful reference for identifying exactly which variables you want to analyze.
How do I pick which specific variables I want?
Rather than scrolling through 7500 table_ids, it’s useful to review all possible top-level subjects (i.e. the first 2 digits after the B or C):
- 01 Age; Sex
- 02 Race
- 03 Hispanic or Latino Origin
- 04 Ancestry *
- 05 Citizenship Status; Year of Entry; Foreign Born Place of Birth *
- 06 Place of Birth *
- 07 Migration/Residence 1 Year Ago
- 08 Commuting (Journey to Work); Place of Work
- 09 Relationship to Householder
- 10 Grandparents and Grandchildren Characteristics *
- 11 Household Type; Family Type; Subfamilies
- 12 Marital Status; Marital History
- 13 Fertility *
- 17 Poverty Status
- 18 Disability Status *
- 19 Income
- 20 Earnings
- 21 Veteran Status; Period of Military Service
- 22 Food Stamps/Supplemental Nutrition Assistance Program (SNAP)
- 23 Employment Status; Work Status Last Year
- 24 Industry, Occupation, and Class of Worker
- 25 Housing Characteristics
- 26 Group Quarters *
- 27 Health Insurance Coverage
- 28 Computer and Internet Use *
- 29 Citizen Voting-Age Population *
- 98 Quality Measures *
- 99 Allocation Table for Any Subject
* Not included in SafeGraph’s Open Census Data
Cheat Sheet: Here are some of the most commonly referenced attributes in the census:Population sizes:
- Total Population: B01001e1
- Population by Age and Sex: B01001*
- Population by Household Incomes: B19001*
- Population by Education Level: B15003*
- Population by Race: B02001*
- Population by Hispanic Ethnicity: B03003*
- Population by Race & Hispanic Ethnicity: B03002*
- Population by Household Type: B11001e*
* wildcard character
Summary Statistics:
- Median Household Income: B19013e1
- Aggregate Household Income: B19025e1
- Per Capita Income: B19301e1
- Median Age: B01002e1
Once you know which table_ids you want to include, the documentation explains exactly in which files to find them (hint: if you want the variable B01002e1 it is in the data file cbg_b01.csv).
Step 2: Join Open Census Data to your Data
Clearly the best way to join your data to the Census data is on the FIPS code (the primary key of Census data). For one-offs you can manually look up FIPS for census block groups using an address or a point, we recommend this tool, but there are many resources.
A programmatic workflow generally looks like this:
List of places –> List of lat,long coordinates → Geospatial Join with CBG geometries (point-in-polygon) to link to FIPS
If you are starting with SafeGraph Places, then you already have latitude, longitude coordinates for every place. If not, you will need to geocode the data using a tool like the ArcGIS geocoder or the Google Maps API, or match the data to a safegraph_place_id to get geospatial coordinates.
To complete the Geospatial join you will need the CBG geometry boundary data. The CBG geometries are available as a geojson or shapefile from the USA government. Good luck googling for them. Don’t worry, we have you covered: SafeGraph includes this data (as geojson) in our Open Census Data, and we highly recommend using it. FYI here is a python working notebook that shows exactly how to do the geospatial join in Python.
You’re done. It’s that easy.
Now you have rich Census data joined to your original places data and you can answer your burning demographic questions. Does this new candidate retail site cater to my target audience? Do my ideal customers live near these billboards? Do certain demographic factors correlate with cancer diagnoses?
For a full, interactive, coded and working example of using Open Census Data to answer a simple demographics question about a place, see Beginners Guide to Analyzing Census Data: A Python Notebook.
More Resources:
- For a full, end-to-end, working example of using Census data to answer a simple demographics question about a place, see Beginners Guide to Analyzing Census Data: A Python Notebook.
- For a working example of geospatial joins using geopoandas in python, see: Point-in-Polygon Geospatial Join: A Python Notebook.