If we want to massively accelerate artificial intelligence and improve human lives, we need to democratize access to data.

Past civilizations built grand libraries to organize the world’s knowledge. These repositories of information focused on cataloging, aggregating, organizing, and making information accessible so that others could focus on learning and creating new knowledge.
AI and machine learning systems also need repositories of information from which to learn — and right now everyone is building their own. If different groups of people focus on organizing data versus building AI, the progress of intelligent computers will massively accelerate.
Computers are not learning fast enough.
Despite all the progress in machine learning (ML), most of our computers (and their applications) leave much to be desired. In her essay Rise of the Data Natives Data Scientist Monica Rogati explains:
There are frustrating times ahead…autocomplete and autocorrect are everywhere — and we make fun of them when they don’t work. We’re frustrated when our GPS…shows us a restaurant 1,000 miles away…If we haven’t yet fixed the small things, how can we be trusted with the innovations that would really enhance all our lives?
When it comes to AI improving human lives, the pace of progress has been super slow.
Big Data is MUCH better.
Many state of the art AI and ML applications would be dramatically improved with more training data. This is hugely important. Google is one of the best AI and ML companies in the world. Why? Peter Norvig, Research Director at Google, famously stated that “We don’t have better algorithms. We just have more data.”
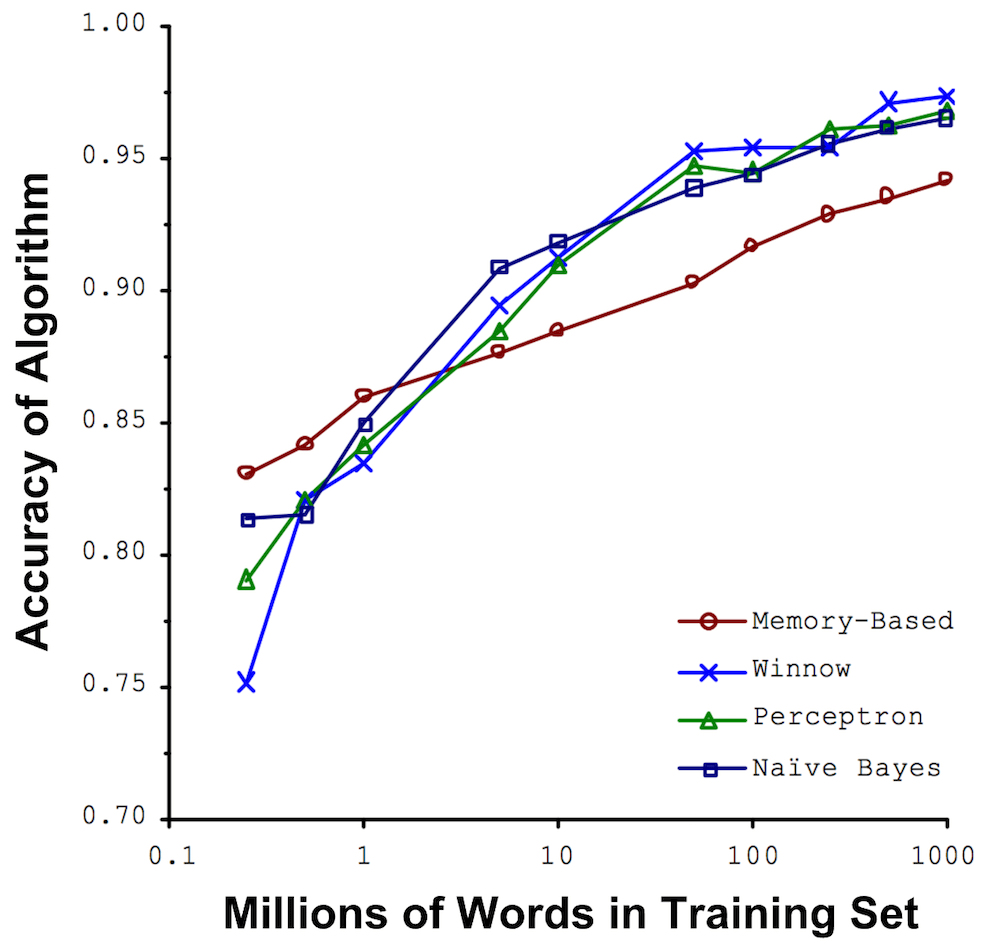
Michele Banko and Eric Brill at Microsoft Research wrote a now famous paper in support of this idea. They found that very large data sets can improve even the worst machine learning algorithms. The worst algorithm became the best algorithm once they increased the amount of data by multiple orders of magnitude.
Machine learning and artificial intelligence is fueled by data.
Good, high quality data serve as truth sets about the world from which our machines can learn. And most AI and ML is likely under performing because getting access to great truth sets is very hard.
The Problem: Organizing the past at scale is hard.
Organizing the past at the scale required by AI and ML is hard. Before a company can actually work on their AI or ML they need to solve four key challenges:

1) Acquire the data
2) Host the data
3) Prepare the data
4) Understand data privacy
To understand the difficulty, let’s briefly discuss what each of these challenges entail.
Challenge #1: Acquiring Data – companies need access to great truth sets
This is where companies like Google and Facebook have a huge advantage — their businesses generate treasure troves of data.

For example, to build a neural network that could recognize human faces and cat faces, Google used 10 million YouTube videos. That is a data set to which literally no one else in the world had access. Four years later (just a few months ago in the Fall of 2016) Google released a large-scale dataset of labeled photos and videos to help the machine learning community — because they recognize how valuable this dataset is for everyone else.
But if you are a start-up doing image classification or a new self-driving car company (like Oliver Cameron), or a new search/query technology (see Daniel Tunkelang), or trying to revolutionize health care (see Jeremy Howard), or any other valuable AI application … even if you have $800 million in funding … you have very little data.
An under appreciated fact: @google is doing what no major AI company is doing — sharing massive datasets, and models pretrained on them.
— Delip Rao (@deliprao) September 30, 2016
You might need to contact hundreds of companies and negotiate major business development (BD) deals to try to license data. It will take a huge effort — sometimes many years — and a lot of money. You might need to spend tons of engineering time and person hours and technological innovations to aggregate and organize and label data from open sources.
For Uber to work on self-driving cars it announced a $500 million initiative to make maps (organizing the past). $500 million!!!
If companies can’t figure out how to get truth sets, they can’t build smart machines.
Challenge #2: Host the Data
Let’s assume you have access to a great truth set — you also need to stand it up (host it in some way that your data scientists and engineers can work with it). Because the best datasets are very large, you need a cloud infrastructure and distributed processing technologies and your share of hot-shot, high-priced, back-end data engineers to make the data queryable and actionable.
Your best engineers spend most of their time just managing your big data infrastructure, pipelines, and query layers.
Challenge #3 Prepare the Data
Then, even the best sources — even data you generate yourself — will be dirty. Your data will have errors, typos, mislabels, holes and need tons of cleaning. Your ML engineers and data scientists will spend most of their time just getting your data ready to use. It’s a cliche: data scientists spend 80% of their time just preparing the data. And this is the least enjoyable part of their job.
data scientists spend most of their time massaging rather than mining or modeling data https://t.co/yAF5qA4Dzr
— Auren 𝐇𝐨𝐟𝐟𝐦𝐚𝐧 (@auren) November 26, 2016
The size of this problem has led some to joke that the most impactful applications of AI would be to help data scientists clean their data faster.
I’m starting to think that the best, first application of AI should be: data munging.
— Michael E. Driscoll (@medriscoll) May 22, 2015
If the process of building smart computers itself creates new human problems for smart computers to solve — then we can see how progress will be slow.
Challenge #4 Understand Data Privacy
If you are trying to solve the most important questions of society, you probably are working with data about people. That means you need to become an expert on privacy and protecting consumer data. This requires significant ethical and legal sophistication.
You must understand the evolving regulatory landscape of data privacy. This includes the implications of FCC rulings in the United States and the significance of GDPR in the EU and much more. It requires understanding evolving definitions of PII (personally identifiable information).
Protecting personal privacy and developing next-generation AI are essential and mutually inclusive — but without the right expertise you can fail at both.
The smartest people in data are spending too much time organizing the past.
Our point is this: Almost all the super-smart data people want to focus on building AI and machine learning applications to improve human lives. They want to use data to make decisions and predictions about the future and power incredible new technologies — like self-driving cars or super-human medical diagnoses or global economic forecasts. This is great. But instead, they are spending tons of time organizing the past: acquiring data, hosting data, preparing data, and navigating data privacy.
Why does every company that wants to work on AI or ML (or simply wants to incorporate AI and ML into their products) need to reinvent the wheel and develop time-consuming expertise that has little to do with their core business?
An alternative: focus on your strengths and rent your data.
David Ricardo’s classic economic theory of comparative advantage boils down to this: focus on your strengths, trade with others, and everybody wins. Organizing the past and predicting the future are different kinds of expertise — you shouldn’t have to master the former to contribute to the latter. In fact, requiring everyone to master all of these domains is bad for AI and ML as a field because progress will be rate-limited to the handful of big players with the resources to do it.
Just like internet companies use Amazon Web Services to rent access to hardware, ML and AI companies should rent access to data. Innovators should focus on applying AI and ML to their domains of expertise (cancer, robotics, self-driving cars, economics, etc.). They should rely on other companies with different kinds of expertise to acquire the data, to build appropriate infrastructure, to clean the data, make it easy to work with, and to protect consumers’ privacy.
Democratize access to data.
If people (and companies) focus on their strengths, then some will organize the past and others will predict the future. The barrier to start working on AI and ML will be dramatically lowered. Access to data will be democratized. If we focus on our strengths, the pace of innovation in AI and ML will massively accelerate.
This piece was authored by Auren Hoffman and Ryan Fox Squire. Auren is CEO of SafeGraph and former CEO of LiveRamp. Ryan is Product Manager at SafeGraph and former Data Scientist at Lumos Labs.
If you found this valuable — please recommend and share this post.
Special thanks to inspirations: Oliver Cameron, Michael E. Driscoll, Anthony Goldbloom, Brett Hurt, John Lilly, Hilary Mason, dj patil, Delip Rao, Joseph Smarr
Join SafeGraph: We’re bringing together a world-class team, see open positions.