SafeGraph is thrilled to announce an exciting partnership with AWS and Databricks to make insights about the physical world easier than ever.

Today Amazon launches AWS Data Exchange , a new platform for sharing data. SafeGraph is honored to be a founding data partner for the AWS Data Exchange, launching today with over 20 powerful datasets available for free or for purchase (you need to sign in to your AWS account to see the listings).
SafeGraph is honored to be a founding data partner for the AWS Data Exchange, launching today with over 20 powerful datasets available for free or for purchase.
Also, if you want to learn more about using SafeGraph data in Databricks, register for our upcoming webinar.
SafeGraph Is the Source of Truth for Points of Interest (POI) Data.
SafeGraph is just a data company, that’s all we do.
SafeGraph has two primary datasets:
- Places: Base information about a point of interest (POI) such as location name, address and brand association for top ~5,500 national brands. Available for ~6.1MM POI.
- Geometry: Geometry information for commercial POIs that includes the polygon of the POI and spatial hierarchy metadata defining whether the polygon is contained within another POI. Available for ~6.1MM POI.
AWS is one of the most important cloud services companies in the world. Making SafeGraph data available in the AWS Data Exchange is 100% aligned with the SafeGraph mission to democratize access to data.
The AWS Data Exchange is now hosting over 20+ datasets from SafeGraph, including:
- SafeGraph Core Places — Entire USA (5.3MM records)
- SafeGraph Core Places — USA Gas Stations and Convenience Stores (135k records)
How Do I Work with SafeGraph Data from AWS? Answer: Databricks.
Databricks is a unified analytics platform that enables data science, data engineering and business analytics teams to derive value from data at scale and with ease of use in a collaborative manner.
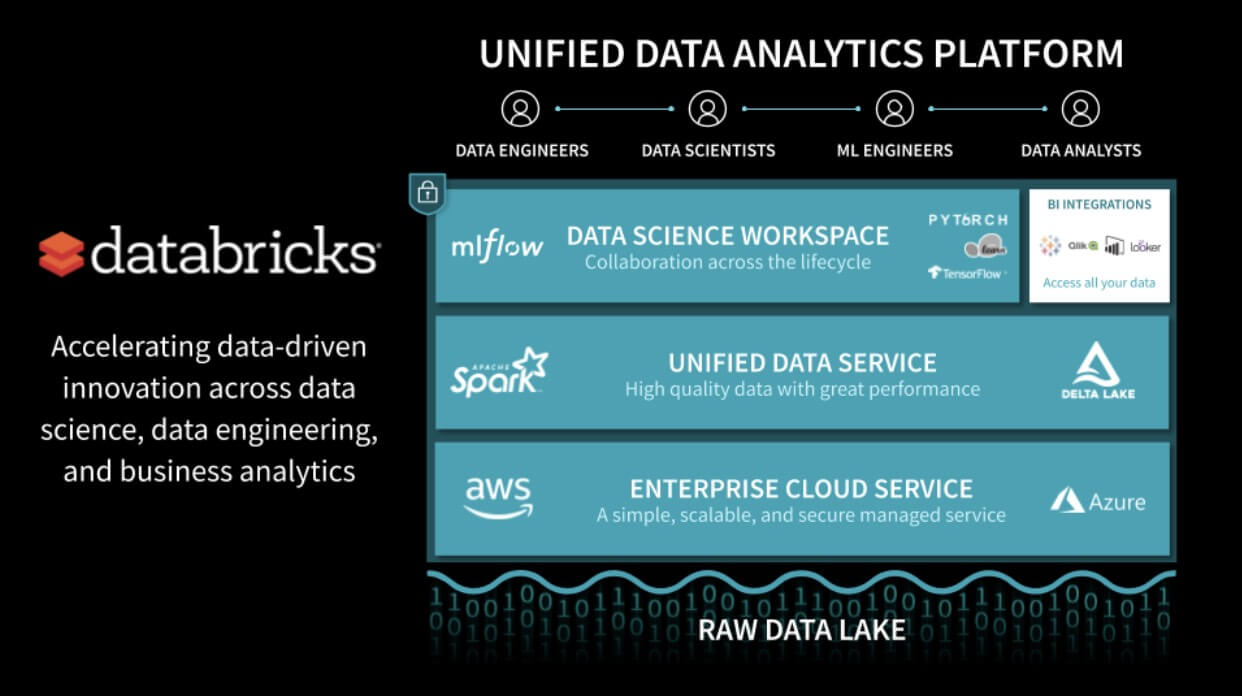
At its core, the Databricks platform is powered by Apache Spark and Delta Lake in a cloud native architecture, which gives users virtually unlimited horse power to acquire, clean, transform, combine and analyze data sets within minutes from a notebook interface, with popular languages of choice (python, scala, SQL, R). Because Databricks is a managed platform, customers do not have to become big data devops gurus to power their analytical needs, which reduces administrative burden, costs and risks of their data driven projects.
How Do We Load SafeGraph Data from AWS Exchange into Databricks Data Lake?
To demonstrate the power of SafeGraph data inside Databricks, we are highlighting two datasets from SafeGraph currently available for free inside AWS Data Exchange.
Getting your data running in Databricks is just a few clicks away. We’ve published full step by step instructions for loading SafeGraph data into Databricks from AWS Data Exchange on the Databricks blog.
SafeGraph + AWS + Databricks
- Reading SafeGraph data from AWS Data Exchange into Databricks is quick and easy.
- Combining these technologies and datasets enables you to answer powerful and precise questions about consumer behavior.
Want to get more SafeGraph data?
There are over 20 datasets available for free or for purchase in AWS Data Exchange. Check them out!
Special thanks to Andrew Hutchinson and Prasad Kona from Databricks and Ryan Fox Squire from SafeGraph for help developing the demonstration notebook and content of this blog post.
