Some of the brightest minds in actuarial modeling, data science, and machine learning work in insurance. That’s because insurance is deeply dependent on using measurable truths about the world (data) to predict the future. Better predictions about the future lead to more accurate risk predictions. More accurate risk predictions mean more precisely written PIFs (policies in force). More precise PIFs means fewer high-risk exposures and more profitable policies, which means a more profitable insurance business. There is a reason self-proclaimed data-nerds have been working in insurance for 100s of years before “data science” was cool, and that’s because in the world of insurance, data is king.

Insurance risk assessment is a three-dimensional, geospatial problem
There are a lot of factors to consider when insuring a commercial business, and many of those are geospatial. If you are selling flood insurance, for example, knowing whether a business is located near a river with a history of flooding as well as how likely that river is to flood again is critical to writing a risk-balanced policy. Similarly, if you are selling fire insurance, you need to know if a business shares a wall with an open-flame commercial kitchen and bakery.
But where does this relevant geospatial data come from?
Roof-top geocodes are not enough to assess co-tenancy risk
Sharing a wall with an open-flame commercial kitchen is a great example of co-tenancy risk. Unfortunately, co-tenancy risk is particularly difficult to assess. Unlike primary data about the business (like where is the business located), the policy-holder may not be fully aware of the relevant co-tenancy information (like what are the surrounding businesses). Most natural disaster-related geographic data—such as knowing whether a given business is located in a flood zone and how much it rains at this location—is collected by governments, changes infrequently, and is available via many GIS solutions. In contrast, point of interest (POI) co-tenancy data changes frequently as businesses open and close or as malls and retail parks are rebuilt or expanded. Accurate, complete, and timely POI co-tenancy data is rarely available in existing GIS solutions.
Imagine that you need to assess the co-tenancy fire risk for a business. Assuming you have access to accurate POI co-tenancy data, the first thing you need to verify is whether the insured business is near another business that has a high risk of fire. This requires knowing:
- Accurate category data about all nearby POI in order to identify potential high-risk neighboring businesses; and
- Accurate roof-top geocodes—also known as “building centroids”—for every business in order to calculate the distance between the insured business and the high-risk POI and then assign it a particular risk value.
But roof-top geocodes are not enough. Being across the street from a high-risk POI does not carry the same risk as sharing a wall or being in the same building, even if the distances between roof-top geocodes are the same.
Co-tenancy data is, therefore, about understanding the geospatial relationships and hierarchies between businesses. Is this business located inside of another business, such as a Starbucks inside a Kroger grocery store? Is this business within its own stand alone building or does it share a parent structure (parent building) with other businesses, as is typically the case for indoor or outdoor malls? The risk of a fire spreading from one business to another is much greater when businesses share a wall or a building.
SafeGraph Places contains rich geospatial co-tenancy data
SafeGraph Places is the most comprehensive and accurate dataset about commercial points of interest, covering 6MM+ POI in the United States and Canada.
SafeGraph Places was built as a geospatial POI dataset from the very start. It goes beyond simply providing essential metadata (i.e. address, category, corporate branding, etc.) to give you access to rich geospatial data, including precise roof-top geocodes, polygon building footprints (2-D shapes), as well as co-tenancy information, such as business and building “parent-child” relationships (i.e. Is this POI inside another POI and/or does this building structure contain multiple businesses?).
The key fields related to co-tenancy data are the parent_placekey and the polygon_class columns.
Let’s apply this to the real world and look at how you can use this data effectively to assess the co-tenancy fire risk for a chain of fitness centers in California.
Case Study: What are high-risk locations for fire damage?
Let’s consider the portfolio of Anytime Fitness (SG_BRAND_6daa255524fe5ac244c3bed9cfbde479) locations in California. At the time of first publication (February 2020), Anytime Fitness had 124 locations across California.
Now, imagine we are tasked with evaluating a commercial insurance policy for these 124 business locations, with the risk of fire damage as a key consideration factor for this policy.
It’s important to note that the risk of any business sustaining fire damage is low (fires are rare), and, moreover, not all POI are equally at risk of fire damage. A clothing store is much less likely to experience an accidental fire than a commercial kitchen or bakery, because the latter have open flames and hot ovens burning all day every day. We need to know what other businesses are in close proximity to each Anytime Fitness location in order to accurately assess the risk of fire damage.
Similarly, as a mitigating factor to minimize the potential risk of fire damage, we want to know how closely located our locations are to fire stations. After all, in the unfortunate event of a fire, the number of seconds and minutes until a fire truck arrives has a significant impact on how much fire damage is incurred. Therefore, locations that are closer to fire stations have less risk of fire damage than locations located far away from fire stations.
For our model, we defined high-risk POI for fires as any POI belonging to the following NAICS:
- 722511 – Full-Service Restaurants
- 722513 – Limited-Service Restaurants
- 311811 – Bakeries and Tortilla Manufacturing (Retail Bakeries)
Our simple fire risk model consists of three components:
- log_num_co_tentant_hr_poi is the (natural log of the) number of high-risk co-tenants. We use natural log to capture the diminishing additional risk of N+1 high-risk co-tenants as N gets large.0 vs 1 high-risk co-tenant has a greater impact than 10 vs 11 high-risk co-tenants.
- dist_to_nearest_hr_poi is the distance to the nearest high-risk POI (in meters)
- dist_to_nearest_fire_station is the Distance to the nearest fire station (in meters).
We combined these features into a simple model to calculate a risk score:
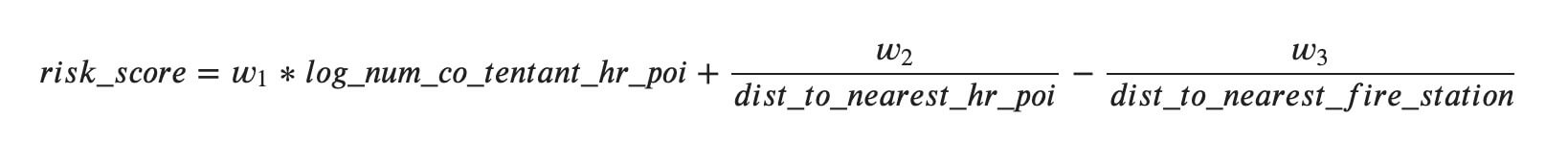
Where:
- w1 is the weight given to having high risk co-tenants.
- w2 is the weight given to the exponential drop-off of risk based on proximity to a high-risk POI. We use the reciprocal function (1/x) to model the diminishing relevance of distance as distance gets large. A distance of 10 meters vs 20 meters from a high-risk POI has a greater impact than the difference between 1010 meters and 1020 meters.
- w3 is the weight given to the exponential drop-off of benefit as you move farther away from a fire station. Again we use the reciprocal function for the same reason described for w2
- The larger the risk score, the higher the risk.
Remember, this is only a simple model for assessing fire risk. In practice, a risk model may account for many other factors, including building materials, weather data, appliance data, foot-traffic data, etc. The weight given to each of these variables can be determined by fitting a model on many years of historical claims data.
Nonetheless, despite its simplicity, our model reveals interesting insights about fire risk when applied to the Anytime Fitness locations in California.
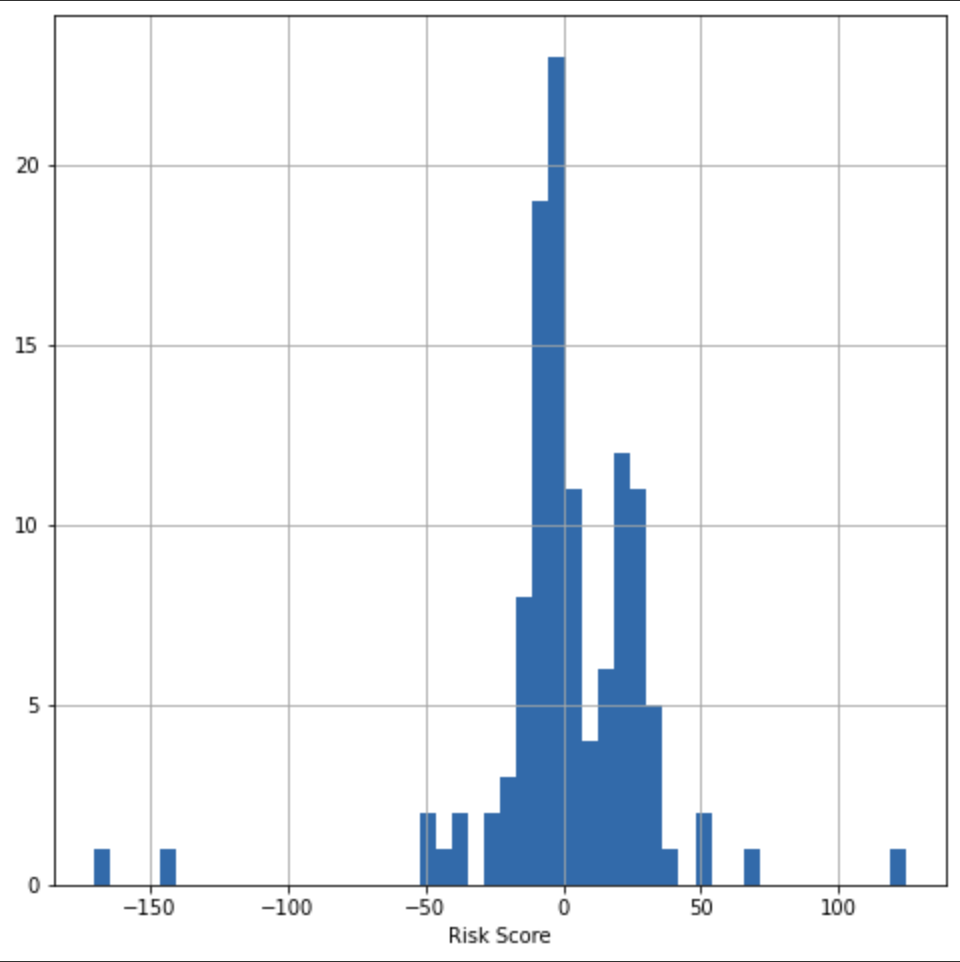
Figure 1 shows a surprisingly symmetric histogram of risk scores for the 124 Anytime Fitness locations. Most locations are clustered around a neutral risk score of 0. However, a handful of Anytime Fitness locations are on the far left tail of this distribution, which means these locations have the lowest risk for potential fire damage. Let’s take a closer look at an example of what this means in a real world scenario.
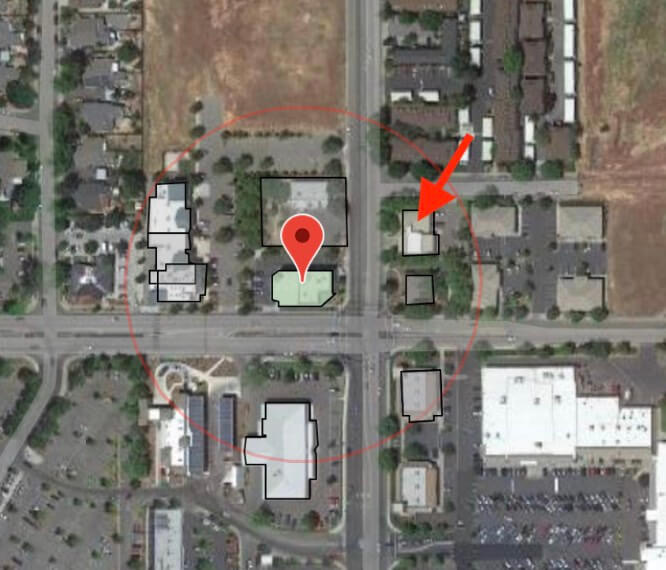
(Placekey: 224-222@5v6-gng-d35) with very low risk of burning to the ground in a fire, according to our model. The red arrow points to the nearest fire station, which dramatically lowers the risk score.
Figure 2 shows an Anytime Fitness with one of the lowest risk scores (-134) in California . What makes it so low risk? First, it has zero same-building co-tenants, which also means it has zero high-risk co-tenants. Second, it’s not near any high-risk POI; it shares a parking lot with a dentist office and a child-care center—both of which are low-risk POI for fire). The nearest high-risk POI is a restaurant located about 72 meters away and across the street. Being that far from a high-risk POI is unusual for Anytime Fitness locations (median = 51 meters). Finally, the red-arrow indicates the nearest fire station, which is very close. Therefore, considering its close proximity to a fire station and the absence of nearby or co-tenant high-risk POI, our model identified this as a very low risk location.
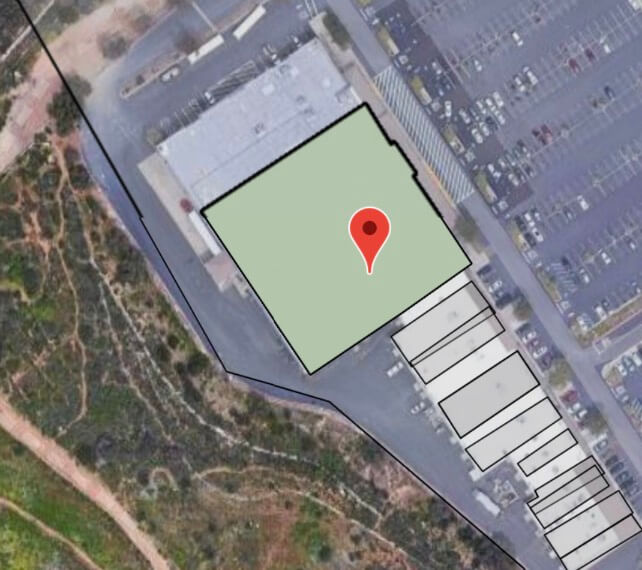
What about the other end of the spectrum? Figure 3 shows the Anytime Fitness location with the highest risk score (+153) in California. This is because it’s located within a strip mall that contains six other high-risk POI for fire. These are all considered co-tenants because the strip mall is one contiguous structure (in the SafeGraph schema, they all share the same parent_placekey). To throw gas on the fire (pun intended), the nearest fire station is 2,800 meters away, much farther than the average distance (median = 1,124 meters).
Better data leads to better insurance risk assessment
This article demonstrates how SafeGraph Places point-of-interest (POI) data makes it possible to build more accurate commercial insurance risk models. Our simple model of fire risk requires the following:
- Roof-top geocodes (building centroids): Knowing exactly where businesses are located in order to calculate accurate distances.
- Spatial hierarchy: Knowing whether a POI is inside of a parent structure and/or sharing a building with other POI.
- Category information: Definitively knowing which businesses are high-risk POI.
- Completeness (high recall): We must have data on every high-risk POI; missing data will create inaccuracies in risk assessment scores.
Traditionally, it has been hard to find accurate data on these attributes for all places. We are changing that at SafeGraph. Our number one focus is to make this data as complete, accurate, and accessible as possible, helping you build better models and more accurate predictions.
Risk modeling is complex and has many variables to consider. Here are some other ideas for how SafeGraph data can enhance your risk-modeling:
- Proximity to POI associated with increased crime or unsavory places.
- Proximity to police stations.
- Square-footage (as a fraction of total enclosing structure).
- Proximity to schools or other types of protected institutions.
- Use polygon_class and geospatial joins to get even more detailed on co-tenancy.
Try It For Yourself
Want to try this model out on more locations? Plug your data into the accompanying Google CoLab Notebook to replicate the results of this blog post.