SafeGraph is a leading geospatial data company that specializes in curating and managing over 45 million global points of interest (POI). Our comprehensive dataset includes detailed attributes such as brand affiliation, advanced category tagging, open hours, and precise polygons.. To produce and deliver the high-precision data product to our customers, we build our data processing stack on top of Apache Spark and run up to 1000+ daily Spark applications.
Traceability in the context of data processing refers to the ability to trace the data changes and consistently recreate the same results from data processing workflows. Traceability is an important factor to deliver accurate data products and enhance the internal capability to debug and fix data issues. Like many other companies, we encountered the significant and prevalent challenge of achieving traceability. Some typical examples include
- Without source code change, the rerun of an “unchanged” Spark application had not produced the same results as its original run and we were not able to pinpoint the factor leading to the inconsistent results
- A table in the data warehouse suddenly exhibits unexpected data distribution. We cannot locate which Spark application wrote unexpected data to the table.
Specifically, we recognize several significant challenges in striving for traceable data processing:
- Complexity of tracing the inputs: The landscape of data processing introduces a multitude of inputs that are constantly changing, intricate to monitor, and pivotal to the outcome of processing jobs. For instance, the content of AWS RDS tables is subject to real-time modifications. Machine learning models might be updated in production without informing downstream users—a complex and sometimes unattainable task. To version and trace all these inputs to the right formats requires complicated considerations ranging from choosing the right data formats to handling the intricate cases like data schema evolution, concurrency control, etc. A comprehensive, all-encompassing solution that can proficiently track these diverse inputs remains elusive in the existing market.
- Conversion overhead from dynamic to versioned Inputs: In our data infrastructure, there exists a diverse array of data sources—ranging from AWS RDS instances to assorted S3 buckets or vendor-specific software housing critical data. These sources, unfortunately, do not offer a well-defined means of versioning data to facilitate traceability. Mandating users to construct data ingestion pipelines for every type and number of data sources would pose an immense burden both in terms of development effort and ongoing maintenance.
- Final stretch to traceability: Even assuming the successful development of the requested technologies, a final challenge emerges: implementing these solutions across thousands of data processing jobs. The shift to versioned table formats like Delta Lake or Apache Iceberg entails recalibrating configurations across a multitude of data processing jobs. This undertaking can be daunting, entailing not only configuration modifications but also the introduction of novel concepts and terminology that necessitate user acclimatization. Thus, the need for a rollout mechanism becomes evident—one that eases the user’s burden, simplifying the process of configuration and concept assimilation. Additionally, we must devise a mechanism for users to seamlessly trace and query the inputs associated with a particular Spark application. This linkage empowers effective debugging and tracking capabilities on the level of individual data jobs. To realize this, the development of an efficient, comprehensive auditing mechanism is essential, one that minimizes dependency on engineers manually adding audit records through specific APIs.
To address these challenges, SafeGraph has developed an architecture called DataChronicle. In this blog post, we will delve into the design and implementation of DataChronicle. It will highlight how DataChronicle operates in the production environment of SafeGraph, serving as a robust foundation for building high-quality data products.
DataChronicle Architecture

The above diagram depicts the DataChronicle architecture. DataChronicle consists of the following components:
- Data Warehouse & Model Registry: Data warehouse and Model registry serves as the components versioning the inputs for users’ Spark applications. Our data warehouse is constructed upon the foundation of the Apache Iceberg format [1]. This choice facilitates not only the storage of data on a large scale but also inherently embeds versioning capabilities at its core. Remarkably, Apache Iceberg seamlessly integrates Changed Data Capturing (CDC) functionality, enabling the highlighting of disparities between successive iterations of data tables. We build our machine learning model registry on top of MLFlow which provides the functionality ranging from versioning ML models to recorded metrics for each ML experimental iteration.
- Ingestion and User Spark applications: Within SafeGraph, we have ingeniously developed an ingestion framework based on Apache Spark. This empowers users to seamlessly configure and initiate Spark applications, which in turn retrieve data from dynamic sources like AWS RDS, S3 buckets, and other vendor-provided solutions. The extracted data is then stored within the Data Warehouse, preserving its fidelity. Furthermore, the User Spark applications read the tables produced by the ingestion framework and create new tables in the data warehouse. The harmonious integration of these applications with the DataChronicle library is pivotal. This library takes charge of generating and tracking versions for an array of inputs utilized by data processing tasks—ranging from fundamental data inputs to intricate machine learning models.
- Audit Logging: A vital facet of our architecture encompasses an automated mechanism dedicated to auditing the input versioning pertinent to each Spark application. These audit records chronicle the versions of data/model/configuration that are associated with each Spark application. This repository of historical versions is securely stored within the audit log storage, forming a comprehensive record of the data processing jobs.
Users have the ability to retrieve the data versions linked to each Spark application which read/write this data within the audit storage. These version numbers can then be utilized as parameters when initiating Spark applications, with the intention of replicating specific results. Moreover, leveraging the CDC (Change Data Capture) table within the data warehouse can assist users in precisely identifying any anomalous alterations in the data.
In the next sections we will give details of each component in DataChronicle.
DataChronicle Library
The DataChronicle library is central to the DataChronicle architecture. It acts as the interface connecting data processing jobs with the data warehouse and model registry. Through its APIs, jobs can read/write versioned tables in the data warehouse and access data models from the registry.
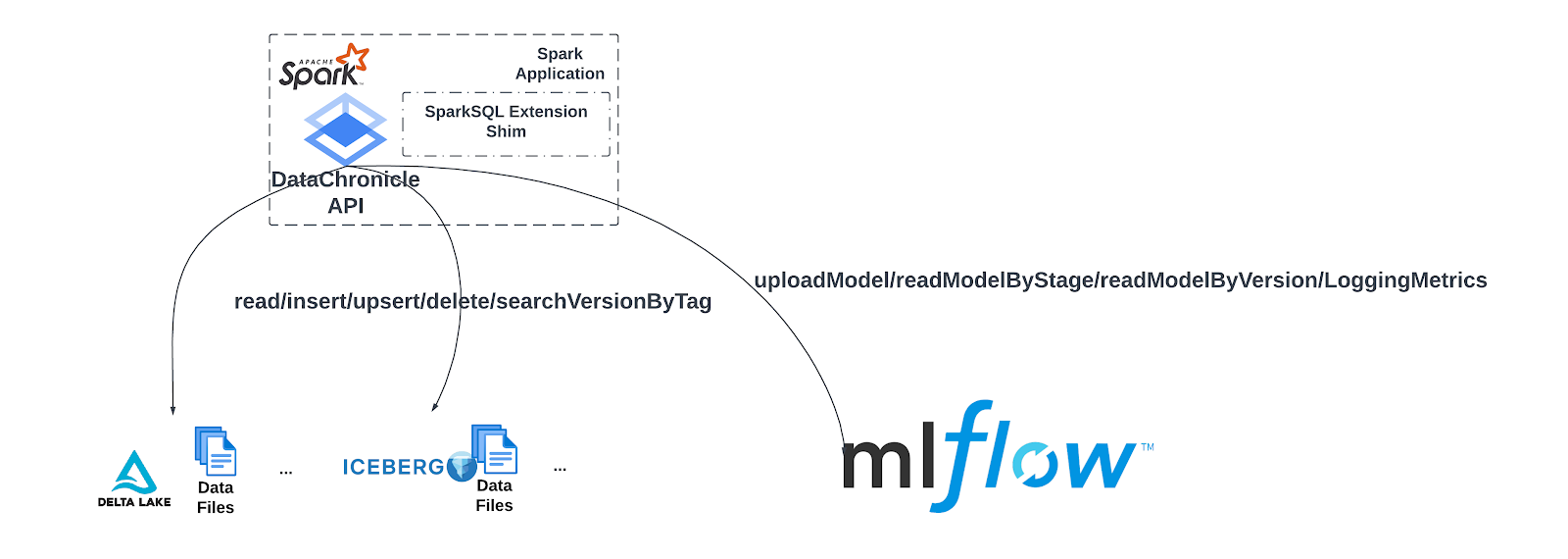
The above figure shows how Spark applications interact with the data warehouse and model registry through the DataChronicle APIs. DataChronicle library serves in two purposes
- Provides an abstraction over underlying table formats (e.g. Delta Lake and Apache Iceberg) as well as the model registry implementation (e.g. MLFlow)
- Provides consistent configuration across all Spark applications in SafeGraph for easier management and to avoid confusion
Unified Abstraction
Instead of exposing the APIs from Apache Iceberg and MLFlow to users directly, DataChronicle masks the technical details and provides unified APIs like read/insert/upsert/delete for data warehouse and uploadModel/fetchModelByStage/fetchModelByVersion for model registry.
This design significantly simplifies our data platform engineering work and makes it future-proof.
As we illustrated in the above figure, when users create a new table managed by the DataChronicle library, they have the option to choose either Delta Lake or Apache Iceberg as the underlying format. Once the format is selected, users can utilize the DataChronicle library APIs to generate versioned tables and perform a wide range of operations, from basic tasks like reading and writing to more advanced tasks like incremental reading and upserting. There are 2 major reasons leading us to design an abstraction on top of Delta Lake and Apache Iceberg:
Uncertainties of open source projects: During the initial phase of our endeavor to establish a foundation for traceability in data processing jobs over two years ago, we encountered notable uncertainties surrounding the open-source projects Delta Lake and Apache Iceberg. In particular, Apache Iceberg was still in its early stages of development with various missing features and bugs. Concerning Delta Lake, we encountered challenges when relying on the open-source version of Delta Lake, as it significantly differed from the private version used by Databricks.
Complexities in Delta Lake/Apache Iceberg: Another key reason driving the development of an API layer on top of Delta Lake and Apache Iceberg is the intention to shield users from certain complexities inherent in these two formats. For instance, with Delta Lake, the absence of dynamic partition overwrite led to using replaceWhere [2][3]. Educating a growing team on its use became challenging, prompting the creation of DataChronicle library APIs to generate replaceWhere statements automatically. Similarly, earlier Apache Iceberg versions posed schema “time-traveling” difficulties [4], addressed by APIs that abstracted these intricacies.
The unified abstraction offered by the DataChronicle library allows us to swiftly establish the groundwork for traceable data processing while ensuring adaptability to future advancements in open-source technology. We began with Delta Lake due to its robustness and gradually transitioned to Apache Iceberg, which evolved to be more mature and gained more community traction. By encapsulating Delta Lake APIs within DataChronicle library APIs and calling them in data processing jobs, the shift to Apache Iceberg required minimal adjustments. Users are not burdened with learning new concepts or SQL commands exclusive to Apache Iceberg; they continue seamlessly with familiar DataChronicle APIs. Migration mainly involves specifying Apache Iceberg instead of Delta Lake as the format when creating versioned tables.
Consistency Across Data Processing Jobs
Providing a consistent handling strategy for various scenarios is pivotal in averting confusions and unexpected behaviors across data processing jobs.
One of the example scenarios we address is how we deal with the changed schema between two versions of data. The silent changed schema in upstream is one of the most common root causes of cascading failures in the downstream. Inconsistency between data processing jobs in this aspect, e.g. some silently allow schema changes and some explicitly disable that case and bring even more challenges. Within the DataChronicle library, we adopt a conservative approach of disallowing schema changes by default. Nevertheless, we offer users the flexibility to enable schema changes and configure notification mechanisms, including Slack integration.
Another example is about concurrency control. This addresses situations where multiple Spark applications or threads within a single Spark application use the same version of an Apache Iceberg table as input but generate diverse outputs via different data transformations and then concurrently commit the outputs as the new versions. A uniform strategy for this scenario simplifies user tasks and boosts job reliability without failing conflicted commits too aggressively.
For instance, we enable up to 1000 retries for append-only concurrent commits from the same Spark application. Additionally, we utilize a distributed lock based on DynamoDB to coordinate commits across various Spark applications, sparing users from intricate distributed system challenges. The consistent distributed locking strategy ensures consistent performance during concurrent commits, without users needing to tackle extra complexities.
Ingestion Framework
The purpose of the ingestion framework is to enable users to easily pull data in dynamic sources like RDS, Label Studio and S3 buckets, etc. and save them in Apache Iceberg format in the data warehouse.
As shown in the below figure, we build our ingestion framework on top of Apache Airflow and Spark. Airflow serves as the orchestration engine to periodically trigger the job and Apache Spark is the main processing engine responsible for data reading and writing.
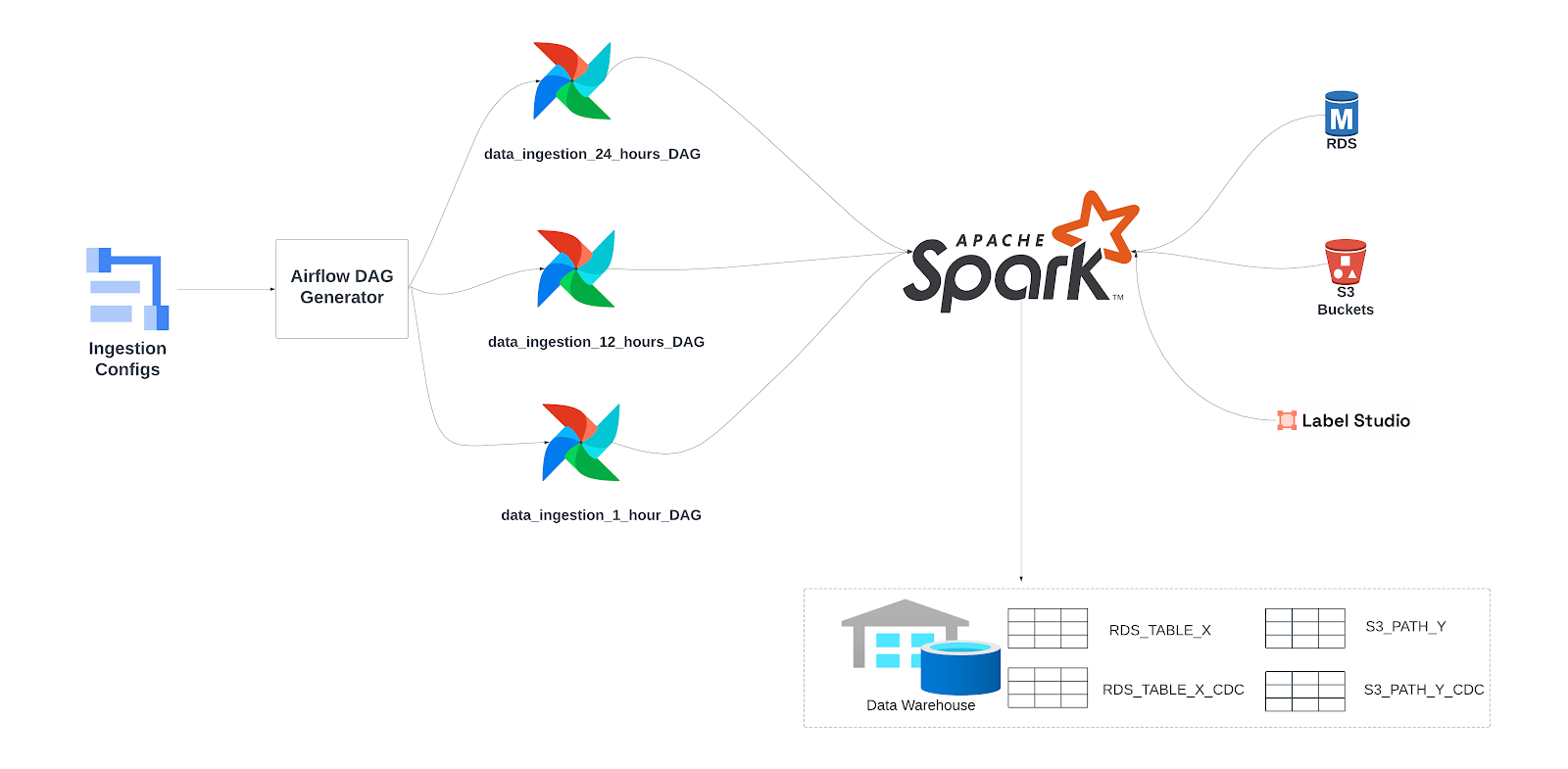
Dynamic Ingestion DAG Generation
Users in SafeGraph can easily define their ingestion Spark applications using a YAML file, which is hosted on our config server [5]. Below is a YAML configuration that demonstrates setting up a daily job for ingesting data from an S3 bucket and an hourly job for ingesting data from an RDS source.

Tailoring our approach to diverse data sources, we grant users distinct configuration capabilities. As an example, users can define configuration entries for Spark applications to effectively read CSV files from S3. For instance, they can specify the data source type with source_type (s3 or aws rds), they can define the s3 inputs format with source_s3_format, e.g. csv, they could also regulate the behavior of Spark applications behavior like whether to automatically change the ingested table schema with merge_schema. These configurations extend to source-specific Spark configurations like specifying whether the CSV file contains headers, etc.
For the streamlined scheduling of data ingestion Spark applications via Airflow, we’ve engineered a DAG generator within our Airflow environment. This dynamic generator loads the aforementioned YAML file from the configuration server, crafting a unique DAG for each designated scheduling interval. Within each DAG, individual airflow tasks are automatically instantiated, and each task corresponds to the specific data sources outlined in the configuration.
This design elegantly abstracts the intricacies of data ingestion into a data warehouse, shielding users from unnecessary complexities. Their sole requirement is to draft a YAML file and commit it to our dedicated configuration server. Our ingestion framework seamlessly manages all aspects, encompassing tasks spanning data reading and writing, as well as the orchestrated execution of Spark applications.
Changed Data Capturing
We empower users not only to generate standard ingested data tables, but also to create Changed Data Capturing (CDC) tables that explicitly highlight additions, deletions, and updates in the data.
To understand how CDC helps to capture changes in the table, take the following as the example. The below table contains 2 columns, v1 and v2. Two rows exist in the table (v1=1, v2=1) and (v1=2, v2=2)

After we UPSERT (v1=1, v2=2), (v1=2, v2=3) and (v1=4, v2=4) based on column v1. The table has evolved into the below

However, with only the above table we cannot tell the origin of each row as there are multiple possible operations which could generate this table.
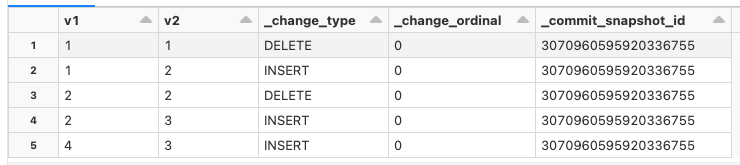
Below is an instance of a CDC table generated using Apache Iceberg.The ensuing CDC table showcases captured data changes following the UPSERT operation. By showing (v1=1, v2=1) and (v1=2, v2=2) have been deleted and the corresponding new rows (v1=1, v2=2) and (v1=2, v2=3) being INSERTED, we can easily build the change lineage. With this table, users can easily track the data changes between two ingestions. Additionally, they can parse the table contents and implement incremental processing practices by only consuming the updated rows.
Final Stretch to Traceability
As emphasized in the beginning of this blog post, to achieve traceability in large scale data processing, we need to develop the right rollout strategy at a large scale in addition to the establishment of technical solutions like the DataChronicle Library. To finish this final stretch, we focus on two problems
- Automatic auditing to associate Spark applications with the versions of inputs
- Rolling out changes to Spark applications to leverage Apache Iceberg
Automatic Auditing Mechanism
While the DataChronicle library and Ingestion framework render data inputs traceable for data processing applications, the automatic auditing mechanism aims to actualize this traceability by linking input versions to their corresponding Spark applications.
The cornerstone of the automatic auditing mechanism lies in the utilization of audit logs, as illustrated in the initial examples of this blog post:
- Disparate Outputs on Re-run: When a Spark application produces divergent outputs upon re-execution, having a record of the data version it initially reads aids in discerning whether the output discrepancy stems from differing inputs.
- Unforeseen Data Distribution: If a table within the data warehouse unexpectedly showcases irregular data distribution, noting which Spark application generated a specific table version aids in pinpointing the origin of the anomaly and streamlines subsequent debugging efforts.
Requiring the users to explicitly make a record for every read/write in Spark application code is not reliable and sustainable. Therefore, we implement the automatic auditing functionality in the DataChronicle library by wrapping the main functionality with the code extracting necessary information like version number, Spark application ID, etc. and sending them to the audit logging storage system.
In our automatic audit logging mechanism, we handle the typical race condition on audit data. a Spark application can have multiple threads read/write Spark jobs, and similarly, multiple Spark applications can read/write the same table at the same time. Considering the following scenario
- Spark application A writes new version of table, version X
- Spark application B writes new version of table, version Y
- Spark application A fetches the latest version number of the table and make an audit log entry into the audit storage system
- Spark application B fetches the latest version number of the table and make an audit log entry into the audit storage system
With the above case, we will get a wrong audit log entry due to the race condition where version Y will be associated with Spark application A.
To resolve this challenge, we attach the version tag to the audit log. The version tag consists of Spark application id, thread id and the epoch timestamp when the audit log entry is generated. Correspondingly, we provide the functionality for searching the version based on the version tag in the DataChronicle library. In the above scenario, even if a new version of table written by Spark application B becomes the latest version of the table , Spark application A can still get the latest version written by itself by searching versions based on the version tag consisting of its own Spark application id, thread id, etc. and eventually generate the correct audit log entry.
With the automatic auditing built in DataChronicle architecture, users do not need to remember to make a record of read/write every time or they do not need to deal with complexities to guarantee the correctness of audit log entries.
SparkSQL Extension Shim
One of the biggest challenges to leverage the power of Apache Iceberg to version the inputs is to roll out changes up to 1000+ Spark applications.
One of the critical changes involves SparkSQL’s Catalog concept introduced in Spark 3.x, utilized by Apache Iceberg to manage tables. Instead of referring to the table as “DatabaseName.TableName”, users need to refer to Apache Iceberg tables as “CatalogName.DatabaseName.TableName”. We need to educate such a new concept in a growing team. Additionally, users can configure inconsistent catalogNames for Apache Iceberg across different Spark applications leading to inconsistency and non-reusable source code.
To resolve this issue, we have developed a module called SparkSQL Extension Shim in the DataChronicle library. As Apache Iceberg registers the catalog name via SparkSQL extension[5], SparkSQL Extension Shim calls the private APIs in Spark to invisibly inject CatalogName configurations into SparkSQL extension. In each Spark application, when users call any DataChronicle library API for the first time, the relevant configuration is automatically injected into SparkSQL extension. Therefore users do not need to make any code change to add configurations.
The SparkSQL Extension Shim not only seamlessly integrates Apache Iceberg with Spark applications but also effectively conceals internal concepts like Catalog to users and eliminates concerns of inconsistent catalog names across various Spark applications.
Summary
In this blog post, we unveiled DataChronicle—the foundation of SafeGraph’s architecture empowering extensive data processing traceability and the capability of shipping precise data products to customers. Central to this is the DataChronicle library, offering versioned input read/write functionalities while maintaining unified abstraction and consistency across Spark applications. Our streamlined ingestion framework simplifies the conversion of dynamic inputs into traceable, versioned forms. Finally, we achieve seamless tracing through automated auditing and integration with SparkSQL, minimizing overhead.