Businesses lose nearly $13 million per year to poor data quality, according to Gartner. A meaningful share of that traces back to location errors: shipments routed to the wrong building, customer analytics tied to wrong coordinates, retail insights built on geocoded data that places a Subway inside a nail salon.
Geocoding sounds like a solved problem. Address in, coordinate out. But the difference between a provider that gets it right 99% of the time and one that gets it right 96% of the time is not 3 percentage points. At scale, it is thousands of misplaced records embedded silently in your data.
This guide covers geocode meaning, how geocoding works, what the three types actually do, how accuracy is measured and why it matters, and where SafeGraph fits into that picture.
What Is Geocoding?
Geocoding is the process of converting a location description into geographic coordinates. That description might be a street address, a place name, a postal code, or even an intersection. The output is a latitude and longitude pair that represents that location on the earth’s surface.
The output coordinate itself is called a geocode. So when people ask about geocode meaning in a data context, the answer is direct: a geocode is the coordinate assigned to a specific location after the geocoding process is completed.
What is geocoded data, then? It is any dataset where records have been enriched with those coordinate values, making them spatially joinable, mappable, and queryable. A list of store addresses becomes geocoded data once each address has been matched to a latitude and longitude. A database of point of interest records becomes geocoded data once each POI carries verified coordinates.
The reverse process, taking coordinates and converting them back into a human-readable address or place name, is reverse geocoding. And when you run the conversion across a large file of records in a single operation rather than one at a time, that is batch geocoding.
Understanding the distinction between these three matters more than it sounds, especially when you are designing a location data pipeline and need to pick the right approach for the right stage.
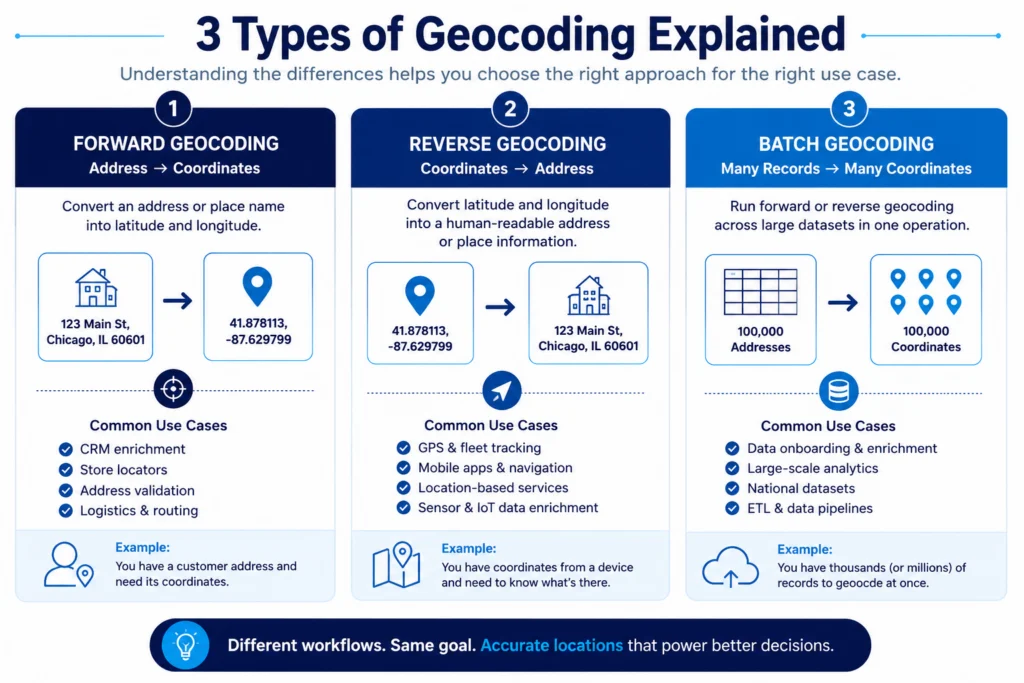
The Three Types of Geocoding
Forward Geocoding
Forward geocoding is what most people mean when they say “geocoding.” You have an address and you need its coordinates. A customer record, a delivery stop, a retail location captured in a CRM form. The geocoder parses that text, matches it to a reference dataset, and returns a latitude and longitude.
This is the foundation of logistics routing, address validation, store locator tools, and virtually any workflow that starts with address data collected from people. If you are building a location data stack and you are sourcing geospatial data from external providers, forward geocoding is almost certainly part of your enrichment layer.
Reverse Geocoding
Reverse geocoding works in the opposite direction. You have coordinates, maybe from a GPS device, a mobile app, or a sensor ping, and you need to know what is at or near that location. What address? What business? What POI category?
The practical uses are wide. Fleet tracking systems that need to log where a vehicle stopped. Mobile apps that display a user’s current address. Analytics pipelines that tie raw coordinate data back to named places for reporting. Any time you are starting with coordinates and need context, that is reverse geocoding.
It is worth noting that reverse geocoding is not just “backward geocoding.” The matching logic is different, and the quality of the underlying POI and address reference data matters just as much, sometimes more, since the question being answered is “what is here” rather than “where is this.”
Batch Geocoding
Batch geocoding is the process of running forward or reverse geocoding across a large dataset in a single operation. If you have 100,000 customer addresses and need coordinates for all of them, you run a batch job rather than processing each record sequentially.
The accuracy implications here are compounded in ways that matter. A 1% error rate across 1,000 records is manageable. Across 500,000 records, there are 5,000 wrong locations embedded in your data without a flag or a warning. That is why the underlying quality of the geocoding data source matters more in batch workflows than in any other context. You cannot manually review 5,000 records. The data has to be right coming out of the geocoder.
Why Geocoding Accuracy Actually Matters
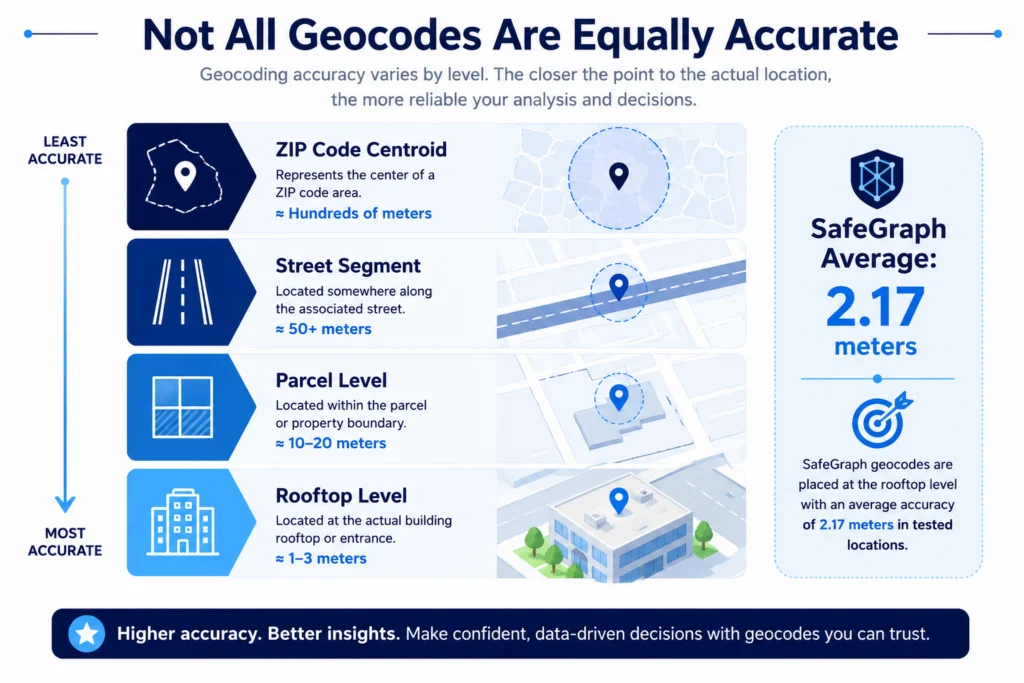
Geocoding accuracy is often treated as a checkbox. You run the addresses, the job completes, you move on. Errors do not announce themselves. A coordinate that is 15 meters off still looks like a valid coordinate. It will plot on a map. It will join to your spatial dataset without throwing an error. The problem surfaces later, when a delivery goes to the wrong building, a footprint analysis places a POI inside the wrong polygon, or a drive-time model anchors to a point on the wrong side of a parking lot.
There are two dimensions of accuracy worth keeping separate.
Positional accuracy is how close the geocode is to the actual real-world location of the address. Rooftop-level accuracy means the coordinate sits on or very near the building itself. Street-level accuracy means it is somewhere on the associated street segment, which could be 50 or more meters from the actual entrance point. For many geospatial data integration workflows, that gap is the difference between a correct spatial join and a wrong one.
Consistency is whether the geocoder’s accuracy holds across all record types, or whether good average accuracy masks a tail of outliers that are quietly wrong. A provider with a strong average but high variance will produce a dataset where most records are fine but some percentage are significantly off, with no way to tell which is which without manual validation.
Both matter. And both are worth asking about before you commit to a geocoding data source.
How Geocoding Works: What Happens Behind the Coordinate
Geocoding does not simply look up a coordinate in a table. Modern geocoders work through several steps, and quality diverges at each one.
First, the address string is parsed and standardized. “123 Main St NW, Chicago, IL 60601” and “123 main street northwest chicago illinois” need to resolve to the same record. Normalization quality is where a lot of providers start to separate. Poor normalization means good addresses fail to match, and bad addresses get matched to the wrong thing.
Next, the parsed address is matched against a reference dataset, a database of known locations with associated coordinates. The quality of this reference data is the single biggest driver of overall geocoding accuracy. Providers pulling from authoritative, regularly updated sources outperform those working from older or less complete references. This is directly connected to why data quality frameworks treat source freshness as a first-order concern.
Then the match is scored. Most geocoders return a confidence score or match type alongside the coordinate. A rooftop match means the coordinate lands on the specific building. A street match means it is on the street segment. A zip centroid match means it is somewhere in the general area. Downstream users often accept any non-null result without checking match type, which is exactly how low-confidence geocodes end up causing operational problems.
Finally, for high-quality providers, machine learning cross-checks and human validation catch the outliers that automated matching might pass. That last layer is expensive, which is part of why it separates serious geocoding data providers from the rest.
Geocoded Data in Practice: Use Cases Across Industries
Geocoded data powers more workflows than most teams realize when they first start mapping them out.
Logistics and last-mile delivery.
Routing engines depend on accurate geocodes to generate directions. A coordinate that lands on the wrong side of a building, or in an adjacent lot, adds friction to every delivery. Compounded across thousands of routes per day, that adds up fast.
Retail analytics and site selection.
Understanding how a potential store location relates to competitor presence, population density, and traffic patterns requires geocoded POI data at the building level, not the street level. Location intelligence decisions built on inaccurate geocodes produce inaccurate trade area analyses.
Marketing and geotargeting.
Address lists geocoded to coordinates support spatial segmentation, proximity targeting, and trade area assignment. The quality of the underlying geocoded data determines which customers get assigned to which markets, and whether those assignments reflect reality.
Commercial real estate.
Property analysis, tenant mapping, and site comparisons all depend on knowing exactly where things are. Even small positional errors can affect catchment area calculations and competitive proximity scoring. For a deeper look at how location data applies here, the guide on location data in commercial real estate is worth reading.
Alternative data and financial analysis.
Funds and research teams using alternative data to track physical-world signals need geocoded POI data that accurately represents where businesses actually are. Mislabeled coordinates can skew the signals that drive investment decisions.
Urban planning and infrastructure.
City planners and infrastructure teams geocode property and facility data to model service coverage, identify underserved areas, and prioritize capital allocation. Accuracy at the parcel level, not the zip code level, is what makes that analysis actionable.
In every one of these use cases, close-enough geocoding creates real downstream costs. The workflows that can absorb 50-meter positional error are fewer than they look.
Comparing SafeGraph’s Geocoding vs. OSM and Google
To understand what geocoding data quality differences look like in practice, SafeGraph conducted a comparative analysis of its geocodes alongside OpenStreetMap and Google in the Little Rock, Arkansas area.
SafeGraph.
Average deviation from actual location: 2.17 meters. Points were consistently placed at or very near the rooftop of the correct building. No significant outliers were found in the sampled set.
OSM and Google.
Average deviation: also approximately 2.17 meters across the full dataset. That sounds comparable until you look at the distribution.
Two outliers stood out. At Schlotzsky’s location, the OSM and Google geocode was 15 meters off, enough to place it outside the building footprint entirely. More significantly, at a Subway located inside a Walmart Supercenter, both OSM and Google placed the geocode at the far end of the building where a nail salon is located. The coordinate was not wildly off in absolute terms. It was just wrong in a way that attributed the position to a completely different tenant.
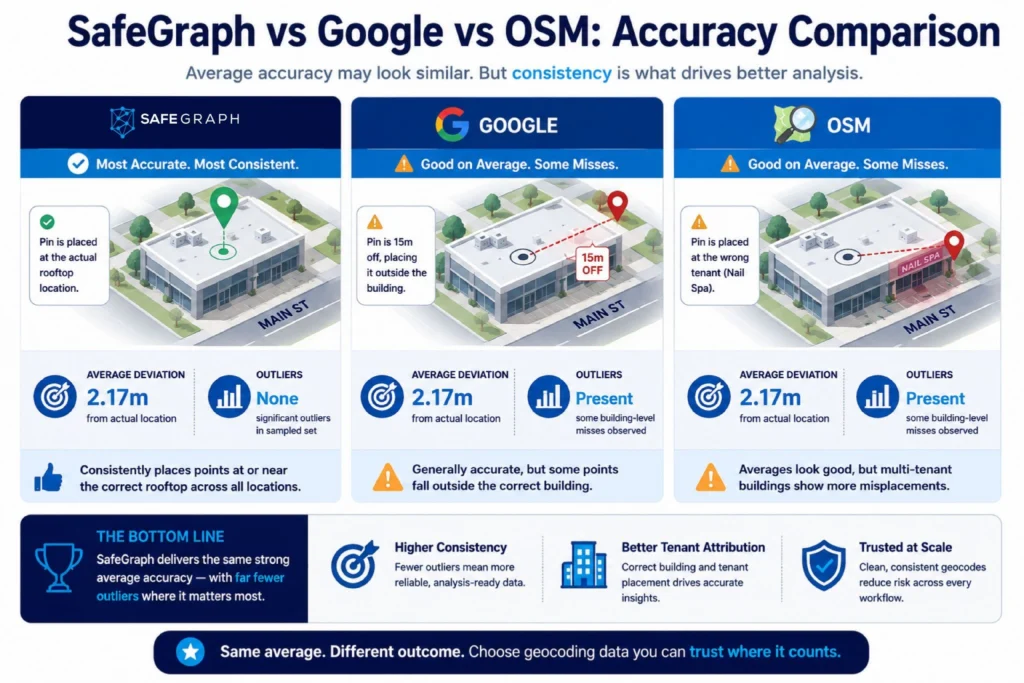
That is the variance problem in geocoded data. Averages can look fine. But if even a small percentage of geocodes are anchored to adjacent businesses inside multi-tenant properties, the downstream effect on any tenant-level analysis is significant. Spatial joins that should hit the Subway end up attributed to a nail salon. That kind of error does not show up in aggregate accuracy numbers. It shows up in your analysis.
Teams building on top of geospatial data types that include multi-tenant POIs, dense urban retail, or large-footprint properties should pay close attention to variance, not just average accuracy.
How SafeGraph Curates Its Geocoded Data
The accuracy SafeGraph delivers on geocoded data is not the output of a single lookup. It is the result of a layered curation process applied to the Places dataset on a continuous basis.
Monthly refreshes.
The Places dataset updates every month. New locations, closed businesses, and address changes are captured on a regular cycle rather than queued for quarterly or annual updates. For geocoded data powering live operations or ongoing analytics, cadence matters as much as baseline accuracy.
Web crawling at scale.
SafeGraph gathers location signals from thousands of public web sources continuously. Those signals feed directly into the geocoding pipeline, surfacing address changes and new POIs as they appear.
Machine learning validation.
ML models cross-reference, validate, and classify POIs at scale. They flag candidates where the geocode does not align with expected building position, category context, or surrounding spatial signals, catching the kind of outlier errors that average accuracy numbers tend to mask.
Human validation.
Ground truth data is developed and maintained by human reviewers, particularly for complex location types: multi-tenant buildings, non-standard addresses, dense commercial strips, and locations where automated geocoding is most likely to produce the wrong result.
Deduplication and merging.
After ingestion, the dataset goes through a rigorous deduplication and merging process that removes duplicate records and consolidates conflicting signals. The final geocoded output is clean and ready to use, not a raw feed that requires downstream cleaning.
For teams thinking through geospatial data management best practices, this curation pipeline is worth understanding because it represents the kind of systematic approach that produces geocoding data you can trust at scale.
Choosing a Geocoding Data Provider: What to Evaluate
Not all geocoding providers are equal, and the differences are not always visible until something fails downstream. When evaluating providers, here are the questions worth asking before you sign anything.
What is the positional accuracy standard?
Rooftop-level accuracy is meaningfully better than street-level for most B2B workflows. Ask whether the provider discloses match types alongside coordinates, and what percentage of records fall into each match tier.
How often is the reference data updated?
A geocoding source built on an 18-month-old reference dataset accumulates errors as businesses move, open, and close. Monthly refresh cadence is meaningfully better than quarterly for dynamic use cases. This is one reason SafeGraph’s approach to data sourcing is built around continuous ingestion rather than point-in-time snapshots.
How does accuracy hold for your specific geography or POI type?
National averages can obscure performance gaps in dense urban markets, multi-tenant commercial properties, or specific verticals like healthcare or hospitality. Ask for benchmark data relevant to your actual use case, not a headline number.
What global coverage does the dataset provide?
Country-level gaps, rural versus urban accuracy distribution, and language and addressing format support all vary by provider. Know where your use case is concentrated before you assume coverage.
What attributes come alongside the geocoded data?
For most B2B applications, coordinates alone are not enough. You also need accurate addresses, category codes, brand affiliations, and open and close signals. A provider that delivers all of that in a single dataset reduces the number of sources you have to maintain and the number of joins that can introduce additional errors.
If you are still evaluating where to source location data more broadly, the guide on where to buy location data covers the provider landscape and evaluation criteria in depth.
SafeGraph Places: Geocoded Data With Full POI Context
SafeGraph Places is a global POI dataset used by thousands of organizations as a primary source of truth for location data. It includes geographic coordinates at rooftop-level accuracy, full address strings, brand and chain affiliations, NAICS category codes, and open and close dates, all refreshed monthly.
For teams that need geocoded data they can build on, not just for mapping but for spatial analysis, retail intelligence, logistics, and site selection, Places provides the coordinate accuracy and surrounding POI context in a single dataset. You do not have to stitch together a geocoder and a separate POI feed and hope they agree.
SafeGraph Geometry extends that further by adding building footprints and spatial polygons, which matters for teams doing polygon-level spatial joins or attribution work where a point coordinate alone is not precise enough.
Closing Thoughts
Geocoding sits so deep in the stack that most teams do not think about it until something breaks. By then the bad coordinates have already made their way into reports, models, and decisions. The damage is rarely traceable back to the source.
What this guide has tried to show is that geocode meaning is not complicated: a geocode is a coordinate, geocoded data is any dataset that carries those coordinates, and the three types of geocoding (forward, reverse, and batch) serve different problems. What is complicated is quality. The difference between a geocoding data source that performs well on average and one that performs well consistently, across multi-tenant properties, dense urban areas, and edge-case POI types, is the difference that actually affects your work.
Accuracy at the rooftop level. Monthly refresh cadence. Variance, not just averages. These are the metrics that matter when you are evaluating geocoding data for anything beyond a quick map.
SafeGraph’s Places dataset is built around all three. If you are working on any of the use cases covered here, whether that is retail analytics, logistics, site selection, or alternative data workflows, the data is worth a look.
Start with a free sample of Places data, or schedule a demo to talk through what your specific workflow needs.