Learn about the power of standards in our DaaS Bible 2.0, and about running a data business on our new podcast, World of DaaS.
Data businesses are generally misunderstood. (That is an understatement).
I’ve spent the last 13 years running data companies (previously LiveRamp (NYSE:RAMP) and now SafeGraph), investing in dozens of data companies, meeting with CEOs of hundreds of data companies, and reading histories of data businesses. I’m sharing my knowledge about data businesses here — written primarily for people that either invest or operate data businesses. I put this together because there is so much information on SaaS companies and so little information on DaaS companies. Please reach out to me with new information, new ideas, challenges to this piece, corrections, etc. And please let me know if this is helpful to you. (this is written in mid-2019).
Data businesses have some similarities to SaaS businesses but also some significant differences. While there has been a lot written about SaaS businesses (how they operate, how they get leverage, what metrics to watch, etc.), there has been surprisingly little written about data businesses. This piece serves as a core overview of what a 21st-century data business should look like, what to look for (as an investor or potential employee), and an operational manual for executives.
In the end, great data companies look like the ugly child of a SaaS company (like Salesforce) and a compute service (like AWS). Data companies have their own unique lineage, lingo, operational cadence, and more. They are an odd duck in the tech pond. That makes it harder to evaluate if they are a good business or not.
Almost all new companies are set up as a service. Software-as-a-Service (like Salesforce, Slack, Google apps, etc.) has been on the rise for the last twenty years. Compute-as-a-service (like AWS, Google Cloud, Microsoft Azure, etc.) has become the dominant means to get access to servers in the last decade. There are now amazing API services (like Twilio, Checkr, Stripe, etc.). And data companies are also becoming services (with the gawky acronym “DaaS” for “Data-as-a-Service”).
Long term (with the caveat that the markets work well and the competitors are rational), a niche for data can be dominated by 1 or 2 players. That dominance does not give these players pricing power. In fact, they actually might have negative pricing power (one of the ways a company may continue to dominate a data market is by lowering its price to make it harder for rivals to compete).
As a data company starts to dominate its niche, it can lower its price and gain more market share and use those resources to invest more in the data … thereby gaining more market share (and the cycle continues). Because data companies have no UI and are not predicting the future (see more in the paragraphs below), the data company can dominate by just having the correct facts and having an easy way to deliver those facts (APIs, queryability, self-serve, and integrations become very important).
Of course, some data markets have no dominant player and are hyper-competitive. These are generally bad businesses. But even in these businesses with “commodity” data, one can potentially get to 50%+ market share by using price and marketing as a lever. (By contrast, it is very hard to make a competitive SaaS category less competitive … we go into why later in this post).
One of the biggest themes in the last ten years has been products that help companies use first-party data better. If you invested in that trend, you had an amazing decade. Those companies include core tools (Databricks, Cloudera), middleware (LiveRamp, Plaid), BI (Tableau, Looker), data processing (Snowflake), log processing (Splunk), and many, many, many more. (note: as a reminder about the power of these tools … while I was writing this post, both Tableau and Looker were acquired for a total price for almost $20 billion!)
These products help companies manage their own data better.
The amount of collected first-party data is growing exponentially due to better tools, internet usage, sensors (like wifi routers), etc. Companies are getting better and better about managing this first-party data. At the same time, compute costs continue to fall dramatically every year — so it is cheaper and cheaper to process the data.

More and more people are comfortable working with data. “Data Science” is one of the fastest growing professions and more people are moving into the field. People are getting more technical (aided by many tools) and communities of data scientists are growing fast — KDNuggets reports “in June 2017, the Kaggle community crossed 1 million members, and Kaggle email on Sep 19, 2018 says they surpassed 2 million members in August 2018.” IBM estimates that the number of people in data science is growing faster than 20% per year.
But unless your company is Google, Facebook, Apple, Amazon, Tencent, or 12 other companies … even analyzing all your data perfectly will only tell you about 0.01% of the world. If you want to see beyond your company’s pinhole, you will need external data.
Even five years ago, very few companies were equipped to leverage external data. Most companies still did not analyze their own data! But as companies get better and better at finding insights in their internal data, they will look externally for data more and more.
At least, that is the bet.
There are an order of magnitude more data buyers today than there were five years ago. IAB reports that even buying marketing audience data (which is traditionally the least accurate of all data) is a massive business and growing.
Nonetheless, there are still very few data buyers today. Most companies want applications (answers), not data (which is essentially a collection of facts).
The only reason to start (or invest in) a data business today is if you believe the number of data buyers will go up another order of magnitude in the next five years.
Data companies are ultimately about selling verifiable facts. So data companies collect and manufacture facts about things. For instance, you could start a data company about the Eiffel Tower, compiling historical facts about the type of steel it is made of, all the changes over the years, the height of the tower, how it responds to wind and other conditions, the biography of Gus Eiffel, and millions of photos of the tower taken from every angle and every hour of the day.
Data companies are about truth. They are about what happened in the past. So much so that SafeGraph’s motto is “we predict the past.” Of course, being accurate (even about verifiable facts) is really hard (more on that later in this post). It is grueling work to get to a point that is even close to being true. And there is no possible way to get to 100% true.
While data companies are about truth, prediction companies (like predicting fraud, predicting credit-worthiness, predicting elections, etc.) are about religion. One framework to think about data companies is truth versus religion and data versus application.
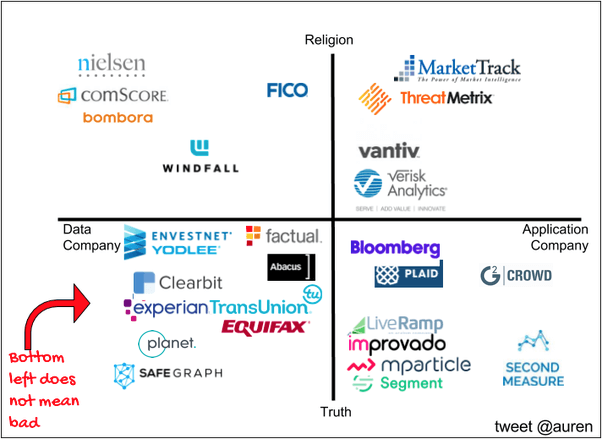
Truth companies focus on facts that happened and Religion companies use those facts to help predict the future. Data companies focus more on selling the raw data while Application companies take the raw data and create some sort of work-flow around it.
One way to think about the market is that Religion companies often buy from Truth companies … and Application companies often buy from Data companies. For instance, SafeGraph (a Truth Data company) has a lot of customers that are applications or religions.
One of the weird things about data companies historically is they often failed on one core value: veracity.
There is a huge trade-off between precision (accuracy) and recall (coverage). In the past, most data vendors were prioritizing coverage over accuracy. This has been especially true about “people” data (see discussion on “People Data” below) for marketing. The more entities one has data about (and the more information about each entity), the less likely that any one data element is correct.
Not too long ago, much of the best data was actually compiled by hand. Some of the biggest data companies still have 3000-person call centers calling and collecting data. As data becomes easier to collect and merge programmatically, we should see more companies with accurate data reach scale.
As companies rely more and more on data (and build their machine learning models on data), truth is going to be even more important. If you are using data to make predictions about the future, then the data that represents the past needs to be highly accurate. Of course, no dataset is 100% true … but good data companies strive for the truth.
One thing to look for in a data company is its rate of improvement. Some data companies actually publish their change logs on how the data is improving over time. The faster the data improves (and the more the company is committed to truth), the more likely the data company will win its market. And there are massive gains to winning a market.
SafeGraph’s President and co-founder Brent Perez always likes to remind me that there are only three core things a data company does:
1) Data Acquisition
2) Data Transformation
3) Data Delivery
There are lots of ways for companies to acquire data and every data company needs to be very good at least one of the ways. Some of the ways to acquire data are:
Your data acquisition might come from thousands of sources. You need to fuse the data together and make it more useful.
Even if you get your data from a few BD deals, you eventually want to graph the datasets together to ask questions across the data. This is where the real magic (and dare I say, “synergies”) happen. Once you marry weather data with the attendance of Disneyland, you can start to ask really interesting join questions. The more datasets you join, the more interesting questions you can ask. (more on this below)
Some transformations might be simple (like local time to UTC) and some might be extremely complicated. Data Scientists spend 90% of their job munging data, not building models. When it really should be the other way around. So simply filtering/deduping data is in itself a valuable transformation.
Questions you want to ask include: How do you join all of the data sets together? What is your “key” (primary or secondary)? How do you ensure you assigning the right data to the right entity (business, person, etc.)? How do you measure that efficacy/accuracy? What is the impact of this downstream for making the data more valuable?
If the data company is employing machine learning (and most good data companies are), this is the step where all the ML magic happens. For instance, SafeGraph uses computer vision and ML to align, register and connect satellite imagery with street addresses and points of interest.
Data transformation is very difficult. As Arup Banerjee, CEO of Windfall Data, reminded me: “You can’t just fix a bug with a simple fix — you can certainly do ‘post-processing’ and remove certain data points, but it isn’t as easy as A/B testing where to put the home button — you need to have a high degree of fidelity and confidence.”
Is it an enterprise solution where they get a big batch file (via an s3 bucket or SFTP)? Is it an API? Is there a self-serve UI? What integrations with existing platforms (i.e. SFDC, Shopify, etc.) do you have?
Does the data come streaming in real-time? Or is the data compiled monthly? It is reliable and timely or variable and unpredictable?
Is the data well documented and well defined? Or does it contain inscrutable columns and poor data dictionaries?
Does the data document its assumptions and transformations? Are there “hidden” filters and assumptions?
Is the data organized into schemas and ontologies that make sense and are useful? Is it easy to join with internal data or other external datasets? Or does the customer have to build their own ingestion ETL pipelines to be able to work with the data?

Data companies need to get leverage and so the data should ultimately fit together with a common key. It is really important to have a data model where you can tie data across disparate elements — so having some sort of guiding theme is really important. For database nerds, think of a theme as a unifying primary key with a series of foreign keys across the dataset. This is not only true for data companies, great middleware companies also should have a central theme to stitch all the data together.
Of course, the best themes are ones that everyone understands, are big enough to collect lots of interesting data, and can be internationalized.
The biggest themes of data business are core concepts that make up our world:
(we dive into each of these “themes” in the appendix at the end)
Data on these static dimensions (people, products, companies, places, etc.) become more valuable when they are temporal and change with time. You can charge more for the data (and align with a subscription model) if it is changing a lot — and, more importantly, you can retain customers because the data is not just a one-time use.
For instance, charging for real-time traffic data can sometimes be more valuable than charging for street maps. That is an example of using time with the physical world.
Another example of time crossed with the physical world is weather data — it changes all the time and is vital for many consumers and industries. In a place like San Francisco that has hundreds of micro-climates, the weather data itself can vary every hour every 100 square meters.
One of the classic temporal datasets is price per stock ticker per time. That dataset is vital to any public market investor. The data goes back over 100 years (the “tick” a hundred years ago might be a day while “tick” today might be a tenth of a second).
In fact, much of the most valuable data is tied to pricing over time. Examples include commodity pricing, rental pricing, prices of goods on Amazon, the Economist’s Big Mac Index, etc.
Data by itself is not very useful. Yes, it is good to know that the American Declaration of Independence was ratified on July 4, 1776 — that allows you to prove you are a smart person and helps you more enjoy your hot dog on Independence Day. But it does not have a lot of use in isolation.
One of the big ways that data becomes useful is when it is tied to other data. The more data can be joined, the more useful it is. The reason for this is simple: data is only as useful as the questions it can help answer. Joining, linking, and graphing datasets together allows one to ask more and different kinds of questions.
One great join key is time. Nowadays, time is mostly pretty standard (that was not true a few centuries ago). And we even have a UTC Time that standardizes time zones so that an event that takes place at the same exact time in Japan and Argentina is represented as such.
Another join key is location (like a postal code).
The more join keys (and joined data sets) you can find, the more valuable those data become.
Let’s consider a simple example. Let’s get data on a ticker and also find out where all the company’s operations are (geographically). Then let’s get a representation of the percentage that each postal code affects sales of the company over time. Then we can join that data (via time and geography) to historical weather to see if the weather had any correlation to the individual sites of operation and ticker price historically.
As you keep joining data, the number of questions you can ask grows exponentially.
As the amount of data grows, the number of questions you can answer grows exponentially.
Which means that if the value of Dataset A is X and the value of Dataset B is Y, the value of joining the two datasets is a lot more than X+Y. Because the market for data is still very small, the value isn’t X*Y yet … but it is possible it will approach that in the future.
Your data will be much more valuable if you enable it to be joined with other datasets (even if you make no money off the other datasets). This is the #1 thing that most people who work at data companies do not understand.
Most people think that they need to hoard the data. But the data increases in value if it can be combined with other interesting datasets. So you should do everything you can to help your customers combine your data with other data.
One way to make data easy to combine is to purposely think about linking it — essentially creating a foreign key for other datasets.
The SIMPLE acronym for data companies — ID or foreign key.
Creating a SIMPLE key to combine your data to other datasets is the most important thing you can do to build a truly valuable data company. Unless you are planning on cornering all the data in the world, your data needs to be graphed to other datasets and the best way to do that is SIMPLE.
I’d like to see a world where organizations are actively encouraged to share data as more data sharing will lead to a world of much more open information.

Margins for most data businesses initially look very bad.
Data companies generally have a lot of trouble attracting Series A and Series B investors because the margins often look very bad in the beginning. Data companies often have a fixed cost of purchasing the core raw materials and for some odd accounting reason, those fixed costs sit in COGS. So the margins initially can look really bad (and sometimes can even be negative in the first year).
But these “COGS” do not scale with revenue. In fact, they are just step function costs as companies go to new markets. Michael Meltz, EVP of Experian, likes to remind me that “incremental margins eventually become extremely attractive at successful data businesses.”
Here is an example of a company’s numbers:

Imagine for a second if you were a Series B investor looking at the business at the end of 2013. Someone with little experience investing in data companies (which is 95%+ of SaaS investors) would look at this company and think this is a long-term 50% margin business.
The reality is that data costs are often a long-term asset and they only sit in COGS because of an odd accounting rule. Data is a fast depreciating asset (because much of its value is temporal), but even the historical data can have a lot of value. And it is buy-once, sell-as-many-times-as-you-can. Gathering the data itself is a significant asset — just the act of compiling the data leads to a “learning curve” moat.
SaaS companies, by contrast, spend gigantic sums on sales, marketing, and customer success. Most of those costs technically go “below-the-line” so the SaaS margins look good. In some cases, those costs really should be below the line and are just really high because the companies are mismanaged (Vista Equity has had massive success in bringing down these costs when it acquires companies). But many of these costs are hidden COGS and the true margin on these SaaS companies are actually not as good as advertised because they are so hyper-competitive.
In DaaS companies, CACs (Customer Acquisition Costs) tend to decline over time (for the same customer types). In some of the best SaaS companies, CACs eventually stabilize but rarely drop significantly (Vista Equity companies seem to be the exception).
One way to see this is ARR (annual recurring revenue) per employee. Another thing to look at is net revenue per employee. Is that metric getting better over time or is it getting worse? Once the company gets to some size (say $20 million ARR), that metric should get better each year unless there is some core strategic investment reason for it to decline. If the ARR/employee is getting better, the business is likely a good one. Companies like Google and Facebook have incredibly high net revenue per employee — like over $1 million per employee. But a lot of the best SaaS companies have between $100k and $200k per employee. The more net revenue per employee, the better.
A good analogy is Netflix, which aggregates consumers worldwide to justify spending money on content. Netflix spends a lot of money on content, but can be amortized among all subscribers. Of course, the analogy breaks down a bit because while data is expensive, it is nowhere near the cost of creating quality video content.
There are some data businesses that look much more like Spotify (which has to pay a percentage of revenue to the content creators). The “margins” in those businesses are much more legitimate and more permanent.
Of course, there are a lot of ways to do data acquisition and they have different cost structures with different account rules. Let’s analyze Priviconix, a fictional company sells data about privacy policies. It parses the privacy policies for the top 100,000 companies and offers analysis on those policies.
(by the way, this is a fictional example, but someone should start a company like this — I am happy to fund this)
There might be a vendor that has already crawled the top 100,000 company web sites and can send you a daily file of their privacy policies. Let’s say that costs you $40,000 a year to buy. That cost sits in COGS (above the line).
Let’s say instead that you decide to do the crawling yourself. Let’s say it costs you $55,000 in salaries a year to maintain the crawl. Those costs (if you can even calculate them) go below the line.
Some CEOs might be tempted to go with the $55k option because it will make her margins look better. But the reality is that the data is the same. Many investors do not appreciate the distinction.
Of course, this depends on the model on sourcing the data. BD deals are really costly, but co-op makes the margins incredibly high (often right from the beginning). Public data is hit or miss depending on the structure, accuracy, and consistently of what you can crawl.
Once you have a flywheel going for a data company, you need to get to market share dominance in your niche. The goal should be to get to over 50% market share. LiveRamp, for instance, has over 70% market share in its niche.
One way to get to 50% market share is to go after a very small niche and relentlessly focus on it. Of course, you will eventually need to move to adjacent niches.
Another way to dominate market share is via aggressive pricing. In the world of SaaS, this is usually not possible because CACs are too high — so lowering LTVs, even temporarily, is usually not a smart option. But with DaaS companies, CACs can be low and one can find ways to get them lower over time. If that’s the case, then there is a case of being aggressive on price using the Bezos “your margin is our opportunity” strategy.
Once you have traction, a third lever to get to market share dominance is via acquisitions. SaaS companies have lots of trouble acquiring their competitors. That’s because SaaS companies have a UI — so merging those workflows is incredibly hard to do (and almost never done right). When SaaS companies acquire, they tend to acquire other products in adjacent spaces so they have more products to sell their current customers (to increase LTVs per customer). This has been an incredibly successful strategy for Oracle, Salesforce, and others. Of course, data companies can also acquire new products to sell into their customers.
But DaaS companies have an additional opportunity to acquire direct competitors. These DaaS acquisitions have the potential to be much easier to be successful (and model) because they can just acquire the customer contracts (this is especially true if they already have the superior product). For instance, if there are two companies selling pricing data on stock tickers, combining those offerings is pretty simple — it is basically just a matter of buying the customer relationships and the ongoing associated revenues.
The goal of getting to market share dominance is not to increase prices on your customers. On the contrary. The goal is to lower your CACs so that you can LOWER prices for your customers. CACs go down because there is one dominant player. LTVs go down too because prices drop. But LTV/CAC ratios don’t go down (they usually go way up). Great DaaS companies act like compute companies (think AWS) — they lower dollar per datum prices every month. So customers get more value for the money and that value compounds over time. (At SafeGraph we aim for minimum 5% monthly compounding benefit for customers — meaning the dollar per data element drops by a minimum of 5% each month).
Compounding is really key for data companies. Data companies build an asset that becomes more and more important over time. But it is really hard to see the compounding in the early days so people often give up. Of course, many super profitable data companies stop innovating and just milk the tedious past work put into compiling the data (that was sometimes done decades ago).
Like all businesses, data companies want to understand their complements and their substitutes. The core complements to data business are cloud compute platforms (like Amazon Web Services (AWS), Microsoft Azure, Google Cloud, etc.) and software tools to process the data (many of which are open-source) and make sense of the data (like many machine learning platforms). The more powerful the tools and the more power available for compute, the more likely a customer will be able to buy and use data.
In fact, if you are in the data-selling business, you can easily qualify your customers by finding out what other tools they are using. A customer spending lots of money on Snowflake and Looker might be much more likely to buy your data.
Another thing to think about is how to commoditize your complement for data. There might be core data that makes your high-priced data more useful. In this case, you want to make sure the customers get access to that data (even if you do not sell it). One way to do that is potentially work to open-source datasets that align with your data. Another way is to join your data with data that is already free (like government data). At SafeGraph, we realized that many of our customers wanted to marry our data with U.S. Census but that data was extremely hard to download and use — so during a hack-day we created a much simpler and free download of Census Block Group data. To learn more about the commoditize-your-complement strategy, check out the detailed posts by Joel Spolsky (more: Joel Spolsky) and Gwern.
Generally, most great SaaS companies sell into a specific industry. On the other hand, DaaS tends to be more horizontal than SaaS.
Data tends to be more horizontal than software. Compute, too, is horizontal. So are many API services.
This is because data is just a piece of the solution. It is just a component. It is an ingredient — like selling high-quality truffles to a chef.
SaaS (software) is the solution. SaaS companies solve problems. So they usually need to get down into the specific issues. While SaaS companies might not be the Executive Chef, they at least position themselves to be the Sous-Chef.
Many DaaS companies sell their data not to the end user but directly to software companies. Most end customers are not yet sophisticated buyers of data — so DaaS companies go for the low-hanging fruit (which are other technology companies). Of course, this is not always the case — Windfall Data has been extremely successful selling its data to non-profits and universities (which are decidedly low-tech).
One interesting thing about the data market is that it historically has been a really bad market to sell into. Very few companies historically have had the ability to buy large amounts of outside data and make use of it. In fact, many companies struggle just to make use of their own data.
Just five years ago, only about 20 of the 11,000 hedge funds were making use of large amounts of alternative data. Today (2019 as of this writing) it is still only about 100 funds. But hundreds of funds are currently making the investment to get better at managing, ingesting, and using this data. So five years from now, it might be 500 funds. 500 is still only a fraction of the 11,000 funds … but it is a significant increase just in recent history.
Because the hedge fund industry is such a competitive and consolidating industry, incremental data points that could produce alpha signals are treated as scarce resources that should not be shared (once other participants know the signal, the alpha shrinks until it is gone). During that time there was a practice of buying exclusive rights to datasets which limited the availability of data to other hedge funds and drove up the prices of comparable data sets. Data acquisition at some of the best funds became a battleground for competitive advantage.
Hedge funds always knew the power of alternative data. Today, that industry finds itself in a more democratized state when it comes to acquiring alternative data and transforming it into insights. Computing power is cheaper, there are more and cheaper vendors that provide comparable datasets and more qualified data scientists and engineers that can be hired to do their jobs better than they had 5 years ago.
Partially this growth is because people are recognizing the power of data. But most of it is due to the growth in the power of the tools to manage and process the data. We use Apache Spark at SafeGraph to manage our datasets. Spark is an incredibly powerful tool and it is significantly more powerful and easier to use than the Hadoop stack (which is what we used ten years ago at LiveRamp).
SafeGraph’s customers benefit from Snowflake, Alteryx, ElasticSearch, and many other super powerful tools. New ML tools that make finding insights from data easier than ever before. These tools do a really important thing for DaaS: they increase the market for companies willing and able to buy and ingest data.
It used to be that only companies with the very best back-end engineers could glean insights from large amounts of data. The best software engineers only want to work for the top technology companies — they are likely not going to want to work for a QSR like Starbucks. But now Starbucks can pay for Snowflake and have the power that only the very best technology companies had five years ago.
Almost every potential customer of every data company will want to evaluate the data before making a large buying decision. Making that evaluation process easy for your customers is essential to any data company. You also want to make it easy for your salespeople (as data companies tend to have a lot of tire-kickers).
One way to accelerate data buying and evaluation is having either a freemium model or some sort of self-serve model (or both). Once companies already use some data, they are pre-qualified (like a PQL — Product Qualified Lead).
If you are a data company and your customers are benefiting from your services (and they have assessed the data and seen it to be true), then you are in position to upsell new data elements to those customers. It is generally important for data companies to be able to upsell additional data products or services over time. Often they start by selling one data product and then upsell customers with an additional catalog of data products over time.
The really important thing is that you maintain quality as you add SKUs. This is hard to do so better to go slow than to dilute your brand. Most of the large data companies today have SKUs of varying quality which really hurts their brand. They would be better off selling fewer SKUs (or selling their competitors’ SKUs).
Data can be sold in many dimensions. By volume, usage rights, SLA, and more.
One thing that all data agreements have in them is specific rights for the buyer. These rights outline what the buyer can do with the data. For instance, many data agreements are time-bound — which means the data needs to be deleted after the agreement is terminated or expires. Most agreements do not let the end buyer resell the data but some might have limited resell rights or discuss what can and cannot be done with derivative data. These data rights can be extremely complicated so it is generally good for your organization to standardize them and not have lots of different data rights for each customer.
One of the problems with “data” is that it is easily copied. For centuries, mapmakers had to contend with their maps being copied and stolen. Starting 500 years ago, many cartographers added fake data to their maps (like fake streets or even countries). Then if they saw that reproduced, they knew it was theirs.
Today many data companies add watermarks to their data. Essentially they will mix in tiny bits of fake data into the real data so they can track it. Super sophisticated data companies will have different watermarks for each customer — so they can trace a data breach to a specific customer.
Many data companies do not actually sell data downloads (“data by the kilogram”) but instead sell SaaS-like per-seat licenses to a tool that allows users to download the data and make use of it. Innovative companies like CoStar, Reonomy, Clearbit, Second Measure, Esri, Verisk, etc. have some version of this. The per-seat subscription model makes pricing simpler and also can make it much easier to protect data. But the per-seat model also means that your company will need to build a user-interface, analytics, and more. So that likely means you are quickly going to be competitive with lots of other solutions (you will not be able to sell your data to your analytics competitors).
Getting data into a workflow can be really powerful. Alex MacCaw, CEO of Clearbit, often reminds me that “the data isn’t useful unless it’s in the place it needs to be. Thus building great integrations and workflows is a key edge for companies competing.”
Your business model and approach will vary greatly depending on your dataset, partners, vertical, and competition.
Right now, most companies spend way more on software than they do on data. They also usually have more than 20 times the number of software vendors as they do data vendors. Alexander Rosen, GP at Ridge Ventures, mentioned “Will this be different in twenty years? I think it will.”
It is hard for data companies to get started because they are just data and not the full solution. It is also hard because so much of the data out there is of poor quality — so you need to get above the noise to get any customers.
The good news is that as software (like Snowflake, etc.) gets more powerful, evaluating the data (during the buying process) will get easier.
Working at a data company is like being an archivist at the Library of Congress. You know your job is important but you also know it is a supporting role that helps other people shine. Your job is to help and support innovators.
There are very few monuments to archivists. They don’t win Nobel Prizes. They don’t write the Constitution, they only preserve it. Being an archivist means being extremely humble. You are an unsung hero. Your job is to help the innovators innovate. You are not the race car driver, you are the pit crew (or maybe just the person who built the wrench).
Some people are naturally excited about the role of being an archivist. They are excited to be in the background and have the intrinsic self-worth of playing the core supporting role. Like the lighting engineers in a Broadway play. But not everyone is suited to be behind-the-scenes and those people should not start or work at data companies.
(note: if you are excited about the mission to be an archivist, join us in a career at SafeGraph)
People: data around a person. Data can be tied together with an email address, social security number, phone number, advertiser ID, cookie, name and address, and many other ties. Data companies that focus on data about people include Experian, Clearbit, People Data Labs, FullContact, and Windfall Data. Middleware companies can also base their data model on people (LiveRamp does that). Almost all companies that use the word “identity” to describe its services is likely based on a “person” theme.
One of the problems with having a “People” theme is the great responsibility of protecting people’s privacy. None of the other data themes (Organizations, Products, Places, Procedures, etc.) have big privacy issues — but for People Data, privacy is THE ISSUE. This is especially true in today’s world of GDPR, CCPA, pending federal regulation, calls for privacy by (and greater scrutiny of) Apple, Google, Facebook, etc. Protecting data on consumers becomes paramount. Even though the consumer is usually not the data company’s direct customer, one needs to do everything to make sure that she benefits from the end use of that data.
As you get more data on people, you also open yourself to attacks from the outside (because data about people can be used to steal money from people) … so security becomes really, really important.
One of the good things about data on people is it’s hard to access and not widely available (or requires a partner network to access). Often the privacy problem can be a feature (instead of a bug), which creates defensibility and a moat around anyone who can aggregate it.
Of course, a HUGE problem with data about people is that it is very difficult for a customer to check if it is true. So most customers discount the data and assume it is really bad (which means it is hard to charge a premium for better data).
The overwhelming winds in the people data business have been moving in a direction that may make it increasingly difficult to have a third-party people data business (that does not have a direct relationship with the consumer). New regulations (like GDPR) can put a lot of burdens on people data companies … but these regulations also create a ton of opportunities for those that do it right and really aim to protect consumers.
Another great theme is one on products (or SKUs). You can aim to cover all products (like the barcode) or a subset of products.
Most of your electronics (like your smartphone, laptop, TV, etc.) carry a serial number that uniquely identifies that device. One could start an entire data company around understanding these serial numbers or other identifiers of SKUs.
One example is R.L. Polk (now part of IHS Markit) which has traditionally collected data about cars. Their aim was to be the best data source about a car. And not just the make and model of a car … but about the actual individual car. So they use foreign keys like the license plate number and the individual Vehicle Identification Number (VIN).
Products are really important and they can be really niche. For instance, you can build a great wine intelligence business selling information on wine bottles. Another nice thing about products is that they have no privacy concerns… you can collect whatever you want on them as long as you do not connect them to a human.
Another good theme historically has been selling data about companies (or organizations).
Dun & Bradstreet runs the DUNS number to uniquely identify a company. DUNS is used by many organizations (including the U.S. government, the UK government, the United Nations, and more). It has been around since 1963 but only became more of a standard in the last 20 years. Dun & Bradstreet signed a contract with the U.S. federal government which was instrumental in making DUNS a standard. For example, companies must register for a DUNS number in order to work with the federal government or file certain documents with the federal government.
Not only do many governments and organizations use the DUNS as a standard, but it is also often required to get certain services (like many bank loans). Because DUNS is a standard, disparate organizations can share information easily on a company. For instance, if a bank wants to repackage its loan to a business, it uses the DUNS number to describe that business so that all other parties can better evaluate the loan (because they have information they trust on the businesses).
Another example of data tied to a company is the stock ticker (and all the financial data that joins on it).
One of the oldest forms of data is information about a place.
Maps have been with us for millennia. Since maps of countries and cities don’t change that much, there has always been a worry from the cartographers that their work would be copied. So starting in the 1500s mapmakers began inserting fake places into their maps — including fake streets.
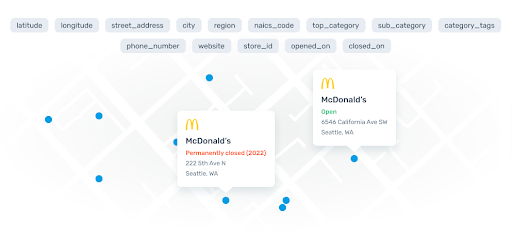
SafeGraph (where I work) focuses on information about Places. As of this writing (June 2019), SafeGraph focuses on places one can spend money (like pay in cash or credit card for something) or can spend time (like parks, etc.). The data includes things like store hours, address, category of place, geometry (e.g. building polygon), IP address of the place, and more. SafeGraph publishes its full schema — as you can see, everything is connected to a place (via the SafeGraph Place ID).
There are many other super successful place businesses.
One amazing places business is CoStar (their market cap is over $20 billion as of this writing). They have detailed information on commercial real estate rentals (like price per square foot, lease length, and more). Originally they collected the data from calling brokers (today they get much of the data directly from the big landlords in a big data co-op).
CoreLogic sells data about residential properties (like last transaction price of a home, number of bedrooms, square footage, etc.). Many of the B2C web sites that have home value data get it from a place like CoreLogic.
A “procedure” is data about a particular action. These are most common in the medical field. For instance, “Lasik surgery” is a procedure — which might have certain expertise, time length, equipment, and price tied to it.
Procedures tend to be more complex data elements than people, places, companies, or products because they are often something that combines many people/products/places into one action. But procedures still have their own IDs, own codes, etc.

Special thank you to Brent Perez (President of SafeGraph), Michael Meltz (EVP Strategy at Experian), Ryan Fox Squire (Product at SafeGraph), Nick Singh (Marketing at SafeGraph), Alex MacCaw (CEO of Clearbit), Alex Rosen (General Partner at Ridge Ventures), Arup Banerjee (CEO of Windfall Data), Erik Matlick (CEO of Bombora), Scott Howe (CEO of LiveRamp), Andrew Steinerman (Equity Research at JP Morgan), Sean Thorne (CEO of People Data Labs), Joel Myers (CEO of Accuweather), Jeff Lu (General Partner at Flex Capital), Mike Babineau (CEO of Second Measure), Will Lansing (CEO of FICO), and many others for their help in putting this together.
If you want to work at a data company, we encourage you to join us at SafeGraph. If you are an entrepreneurial-oriented superstar, please also email me directly.